
Dashboard, który rządził światem
[Nie znam tego słowa – więc czytam: „Dashboard jest specyficznym rodzajem raportu, na którym najważniejsze informacje i wskaźniki powiązane z celami firmy lub organizacji przedstawione są w formie wizualnej’ md]
altershot/dashboard-ktory-rzadzil-swiatem – Dariusz Galczak
Globalny wpływ, którego zbudowanie zajęło „zaledwie kilka godzin”
W styczniu 2020 r. miało miejsce wiele wydarzeń, które są, delikatnie mówiąc, osobliwe. Jednym z nich jest to, że zaledwie 23 dni po tym, jak Chiny poinformowały, że znalazły kilka przypadków „nieznanego zapalenia płuc” w mieście Wuhan, trzy osoby w Baltimore Maryland uruchomiły pulpit nawigacyjny, który został zaprojektowany w celu śledzenia liczby przypadków i zgonów z powodu tej choroby w każdym kraju na świecie. Wszyscy trzej byli związani z Wydziałem Inżynierii Cywilnej i Systemowej na Uniwersytecie Johna Hopkinsa (JHU). Według ich własnych słów, dashboard „został opracowany w celu zapewnienia naukowcom, organom zdrowia publicznego i ogółowi społeczeństwa przyjaznego dla użytkownika narzędzia do śledzenia epidemii w miarę jej rozwoju”[1]. Wraz z pulpitem nawigacyjnym prowadzili również publiczne repozytorium danych o przypadkach i zgonach[2].
Uruchomienie 22 stycznia nastąpiło tak wcześnie na osi czasu Covid, że pierwszy raport sytuacyjny WHO został opublikowany zaledwie poprzedniego dnia, a termin „Covid” nie został jeszcze nawet ukuty. W pierwszym raporcie WHO ogłoszono, że „282 potwierdzone przypadki 2019-nCoV zostały zgłoszone z czterech krajów, w tym z Chin”[3]. Całkowita liczba przypadków poza Chinami wynosiła tylko cztery, a liczba zgonów wynosiła zero. W rzeczywistości tylko sześć zgonów zostało oficjalnie powiązanych z wirusem do tego dnia, a wszystkie z nich pochodziły z Wuhan.
Dla celów porównawczych i aby spojrzeć na to z innej perspektywy, szacuje się, że norowirus zaraża 685 milionów ludzi i powoduje 212 000 zgonów każdego roku[4]. Nie jest nam znany żaden pulpit informacyjny norowirusa gdziekolwiek na świecie.
Chociaż może to być dziwne, że zespół z JHU zdecydował się stworzyć i uruchomić pulpit nawigacyjny dla nienazwanej choroby pomimo tak niskiej liczby przypadków i zgonów w tak niewielu krajach, istnieją możliwe wyjaśnienia, dlaczego to zrobili. Zaledwie 3 miesiące wcześniej JHU był gospodarzem Event 201, „ćwiczeń szkoleniowych… opartych na fikcyjnym scenariuszu” nowego koronawirusa powodującego globalną i śmiertelną pandemię[5]. Co więcej, główny autor pulpitu nawigacyjnego (profesor Lauren Gardner) jest specjalistą w modelowaniu chorób zakaźnych. Niezależnie od tego, co mogą sugerować te fakty, dashboard był, przynajmniej według ich własnych zeznań, wynikiem decyzji podjętej „pod wpływem chwili”, a jego stworzenie zajęło „zaledwie kilka godzin”[6].
Pomimo tego pośpiesznego początku, nowa strona internetowa[7] z pewnością przyciągnęła wiele uwagi w krótkim czasie, szybko stając się główną witryną z danymi dla mediów, badaczy medycznych, władz zdrowotnych i ogółu społeczeństwa, nie tylko w USA, ale także na całym świecie[8, 9]. W ciągu dwóch miesięcy od uruchomienia strona była podobno „odwiedzana 1,2 miliarda razy dziennie”[10], co stanowi prawie połowę ruchu internetowego giganta Google. W ciągu dwóch lat była cytowana przez badaczy medycznych w ponad 8 500 artykułach[11].
„Tablica Hopkinsa stała się wszechobecnym i zaufanym punktem odniesienia, cytowanym przez amerykańskie agencje federalne i główne źródła wiadomości”[12].
Biorąc pod uwagę, jak duży wpływ wywarła tablica rozdzielcza JHU na świat podczas wydarzenia Covid, należy ją szczegółowo zbadać. W szczególności omawiamy tutaj niektóre trudności związane z pozyskiwaniem danych w czasie rzeczywistym, źródła, z których korzystali w celu uzyskania tych danych, sposób, w jaki wprowadzali dane do swojego systemu, bariery językowe związane z tym procesem i wreszcie rolę, jaką mogły odegrać symulacje komputerowe. Artykuł uzupełnia przykład z jednego konkretnego miasta, a mianowicie Nowego Jorku.
Uzyskiwanie danych w czasie rzeczywistym
Nawet z pomocą nowoczesnych komputerów, uzyskanie wiarygodnych danych dotyczących śmiertelności zajmuje zazwyczaj wiele miesięcy (a nawet lat). Na przykład ostatni rok, dla którego dostępne są oficjalne dane dotyczące śmiertelności z wszystkich przyczyn w Kanadzie, to dopiero rok 2020. Krajowy urząd statystyczny, StatsCan, szybko wskazuje, że „opóźnienia w raportowaniu” i „niekompletne dane” są odpowiedzialne za trzyletni wysiłek[13]. Jeśli obecnie organizacja finansowana ze środków federalnych, taka jak StatsCan, publikuje dane dotyczące śmiertelności w ciągu dwóch lub trzech lat, to w jaki sposób JHU mogła uzyskać dane dotyczące zgonów z powodu Covid w czasie rzeczywistym?
Równie trudne jest tworzenie statystyk dotyczących jednego konkretnego patogenu lub wirusa. Na przykład, siedem miesięcy po zakończeniu sezonu grypowego 2017/2018, CDC w USA nadal podawało jedynie szacunkowe dane dotyczące zachorowań i zgonów. Powodem było to, że „dane dotyczące praktyk testowania i zgonów z sezonu 2017-2018” nie były jeszcze dostępne[14]. Data tego oświadczenia to 22 listopada 2019 r. Dokładnie dwa miesiące później pulpit informacyjny JHU został uruchomiony, obiecując informacje o przypadkach i zgonach w czasie rzeczywistym z powodu nowo odkrytego wirusa układu oddechowego, który jest podobny do grypy. Jeśli uzyskanie danych dotyczących śmiertelności i przypadków grypy zajmuje miesiące lub lata, to w jaki sposób możliwe było uzyskanie danych dotyczących Covid w czasie rzeczywistym? Jeśli nie było to możliwe w 2019 r., to w jaki sposób nagle stało się to możliwe w 2020 r.?
Oczywiście na świecie jest wiele krajów, w których raportowanie danych jest niewiarygodne nawet w najlepszych czasach. Podobnie baza danych Human Mortality Database, która śledzi śmiertelność w poszczególnych krajach, jest regularnie opóźniona o dziesięć lat w przypadku wielu krajów[15]. Jak zatem JHU spodziewał się, że będzie w stanie wykreślić zgony z powodu Covid dla każdego kraju na świecie w czasie rzeczywistym? Co ważniejsze, w jaki sposób mogli aktualizować swój pulpit nawigacyjny „co 15 minut”? [1, 16]
Źródła danych dla JHU Dashboard
Dobre dane zależą od dobrych źródeł, a jedynym sposobem na zrozumienie, w jaki sposób pulpit nawigacyjny JHU uzyskał dane w czasie rzeczywistym, jest zbadanie ich źródeł. Istotne jest to, że ich źródła zmieniały się w czasie. Początkowo ich głównym źródłem danych była „DXY, platforma internetowa prowadzona przez członków chińskiej społeczności medycznej, która agreguje lokalne media i raporty rządowe, aby zapewnić skumulowane sumy przypadków COVID-19 w czasie zbliżonym do rzeczywistego na poziomie prowincji w Chinach i na poziomie kraju w innych przypadkach”[1]. Źródło to było zatem połączeniem wiadomości i raportów rządowych.
Ostatecznie zespół w JHU uznał, że DXY zajmuje zbyt dużo czasu, aby uzyskać i opublikować dane, więc rozszerzyli swoją działalność o inne źródła: „Aby zidentyfikować nowe przypadki, monitorujemy różne kanały Twittera, internetowe serwisy informacyjne i bezpośrednią komunikację wysyłaną za pośrednictwem pulpitu nawigacyjnego”. W miarę jak agencje zdrowia na całym świecie tworzyły własne pulpity nawigacyjne, JHU włączył je do swojej listy źródeł[2].
W związku z tym JHU uznała trzy podstawowe źródła informacji inne niż oficjalne strony rządowe:
- kanały Twittera
- internetowe serwisy informacyjne
- bezpośrednia komunikacja wysyłana do dashboardu
Zgodnie z naszą najlepszą wiedzą, nie podano żadnych szczegółów dotyczących którejkolwiek z tych trzech kategorii źródeł. Wszystkie trzy mogą potencjalnie zawierać nieprawidłowe, przesadzone lub całkowicie sfabrykowane informacje. Żadne z nich nie jest publicznie wiarygodne ani nie podlega niezależnej weryfikacji. Nie podano żadnych szczegółów dotyczących tego, kto mógł lub komunikował się bezpośrednio z JHU.
Przeszukiwanie Internetu w poszukiwaniu wiadomości o Covid z pewnością może przyspieszyć proces gromadzenia danych. Niestety, oprócz wyżej wymienionych problemów, wprowadza to również możliwość pętli sprzężenia zwrotnego wzmacniającej hałas. W końcu, jeśli „główne źródła wiadomości” ufały JHU w zakresie dokładnych danych, to w jaki sposób JHU mogło uzyskać swoje dane z (potencjalnie) tych samych źródeł wiadomości?
Duplikaty
Ponadto, nawet zakładając, że wszystkie źródła wykorzystane przez JHU były dokładne, zadanie „łączenia wielu źródeł danych jest złożonym procesem”[17]. Jednym z istotnych wyzwań jest sposób radzenia sobie z duplikatami. Za każdym razem, gdy informacje są uzyskiwane z więcej niż jednego źródła, możliwe jest, że to samo zdarzenie zostanie policzone dwukrotnie. W końcu serwisy informacyjne nie zawierają identyfikatorów zdrowotnych osób wspomnianych w swoich artykułach. W jaki sposób JHU eliminowała duplikaty danych? Czy oznacza to, że liczba przypadków Covid i zgonów zgłoszonych przez pulpit nawigacyjny mogła być dwa, trzy lub wiele razy wyższa niż w rzeczywistości w niektórych regionach? Rzeczywiście, zdarzały się sytuacje, w których użytkownicy danych byli przekonani, że tablica zawiera duplikaty[18]. Na przykład 11 marca 2020 r. jeden z użytkowników repozytorium danych JHU napisał: „Wstawianie zduplikowanych danych do strumienia, który nigdy wcześniej ich nie zawierał, stanowi wyzwanie. Raportowanie zarówno na poziomie stanu, jak i miasta w tej samej kolumnie z pewnością spowoduje problemy”[18a]. Na co inny użytkownik odpowiedział: „CSSE wydaje się podwójnie liczyć przypadki i zgony”[18b]. CSSE („Center for Systems Science and Engineering”) to akronim wydziału JHU, który zarządzał repozytorium danych.
Worldometer jako źródło danych
JHU wyraźnie wymienia Worldometer jako jedno ze swoich źródeł[2]. Sam Worldometer potwierdza ten fakt, mówiąc: „Nasze dane są również zaufane i wykorzystywane przez… Johns Hopkins CSSE”[19]. Ogólnie rzecz biorąc, Worldometer wykorzystuje symulacje komputerowe do raportowania informacji statystycznych w czasie rzeczywistym. Ich symulacje opierają się na rocznych sumach i szacunkach komputerowych. Na przykład, jeśli milion osób ginie co roku w wypadkach samochodowych, to średnio jedna osoba ginie co 31,6 sekundy. Pulpit nawigacyjny Worldometer dla wypadków po prostu dodawałby odpowiednio jedną nową śmierć, niezależnie od tego, czy ktoś faktycznie zginął w tym czasie. Oczywiście Worldometer nie miałby możliwości dowiedzenia się, czy ktoś zginął.
Czy Worldometer używał obliczeń komputerowych do określenia statystyk Covid w sposób podobny do tego, co robią w przypadku wypadków samochodowych? Jeśli tak (i ponieważ nie mogli znać rocznych sum z wyprzedzeniem), czy używali modeli epidemiologicznych, a nie rzeczywistych zgonów, aby oszacować, ile osób umrze w danym roku z powodu Covid? Na żadne z tych pytań nie można odpowiedzieć z całą pewnością. Ich lista źródeł obejmuje tylko instytucje rządowe[19]. Ponieważ jednak pełna lista źródeł nie jest dostępna i ponieważ nie zaprzeczają oni wyraźnie, że używali algorytmów komputerowych, jest całkiem prawdopodobne, że Worldometer używał modeli komputerowych do generowania statystyk Covid. Jest to tym bardziej pewne, że rządy nie byłyby w stanie generować informacji o Covid w czasie rzeczywistym.
W maju 2020 r. CNN opublikowała interesujący artykuł informacyjny, który podkreślił mylący charakter relacji między tablicą rozdzielczą JHU a Worldometer[20]. Odpowiedzi JHU na pytania zadane im w ramach przygotowań do tego artykułu były nieco wymijające i pozostawiły więcej pytań niż odpowiedzi[21].
Podstawowym pytaniem, które pozostaje oczywiście bez odpowiedzi, jest to, dlaczego JHU używał Worldometer jako źródła w pierwszej kolejności? Skoro JHU wykorzystał Worldometer jako źródło, czy oznacza to, że dane leżące u podstaw pulpitu nawigacyjnego JHU były również oparte na modelach komputerowych, a nie na rzeczywistych wydarzeniach? Częściowym powodem, dla którego tak trudno jest odpowiedzieć na którekolwiek z tych pytań, jest fakt, że kod używany przez dashboard nie był open source, co jest często zarzutem stawianym platformie przez użytkowników[22]. Innym powodem jest to, że dane były często wprowadzane do systemu bez wyjaśnienia lub możliwych do zweryfikowania odniesień.
Wprowadzanie danych do systemu
Zgodnie z artykułem Gardner i wsp. w czasopiśmie Lancet, przez pierwsze dziesięć dni po uruchomieniu pulpitu nawigacyjnego JHU „wszystkie dane były gromadzone i przetwarzane ręcznie, a aktualizacje były zazwyczaj wykonywane dwa razy dziennie”[1]. Z logistycznego punktu widzenia było to wykonalne, ponieważ w tym okresie było tak niewiele przypadków i zaangażowanych było tylko kilka krajów.

Lauren Gardner, żródło: JHU https://systems.jhu.edu/lauren_gardner/
Jeśli chodzi o dokładność danych, twierdzili oni, że „[przed] ręczną aktualizacją pulpitu nawigacyjnego potwierdzamy liczbę przypadków w regionalnych i lokalnych departamentach zdrowia… a także w miejskich i stanowych organach ds. zdrowia”. Ustalono już jednak, że ani Kanada, ani Stany Zjednoczone nie były w stanie przedstawić danych dotyczących śmiertelności lub grypy w ciągu sześciu miesięcy. W jaki sposób zatem nie tylko Kanada i USA, ale ostatecznie każdy kraj na świecie, dostarczał dzienne liczby przypadków i zgonów, które JHU mógł wykorzystać do weryfikacji?
Próbując odpowiedzieć na to ostatnie pytanie, zbadano strony internetowe Statistics Canada, aby zobaczyć, w jaki sposób uzyskali dane dotyczące Covid. Stwierdzono, że StatsCan zrobił to samo, co zespół JHU, ponieważ wykorzystał również „techniki skanowania stron internetowych w celu zebrania odpowiednich danych z różnych stron internetowych na temat COVID-19″[23]. Ponieważ nie podano informacji o tym, które strony internetowe zostały przeskanowane, wysłałem e-mail do StatsCan, aby uzyskać listę. Ich uprzejma odpowiedź brzmiała: „Statistics Canada nie będzie mieć pełnej ostatecznej listy wszystkich potencjalnych stron internetowych wykorzystywanych w web-scrapingu podczas pandemii”. Podano dwa powody: po pierwsze, zaangażowanych było kilka działów, z których każdy miał inne procedury, a po drugie, kwestie poufności. StatsCan zasugerował skontaktowanie się z Kanadyjską Agencją Zdrowia Publicznego (PHAC). Jednak PHAC polegał na StatsCan w zakresie informacji, a StatsCan zajmował się skanowaniem stron internetowych, a nie PHAC[23]. Czy ta odpowiedź oznacza, że StatsCan nie wie, skąd wzięli dane dotyczące Covid? A może oznacza to, że wiedzą i nie chcą dzielić się swoimi źródłami z opinią publiczną?
Odpowiedź od StatsCan pozostawia pytanie, czy ich informacje pochodzą z pulpitu nawigacyjnego JHU. Biorąc pod uwagę, jak popularny stał się pulpit nawigacyjny JHU, że został wyraźnie zaprojektowany, aby umożliwić organom służby zdrowia śledzenie wybuchu epidemii, że był cytowany przez amerykańskie agencje federalne, że był szeroko stosowany przez badaczy medycznych i że StatsCan skrobał sieć, aby uzyskać ich dane, jest całkiem prawdopodobne, że StatsCan to zrobił. Nawet jeśli Kanada tego nie zrobiła, jest więcej niż prawdopodobne, że niektóre kraje przyjęły dane JHU jako własne. W jaki sposób JHU mógł potwierdzić swoje dane z organami służby zdrowia, jeśli te same organy służby zdrowia otrzymywały dane od JHU?
W związku z tym istnieje bardzo realna możliwość, że JHU przesłał dane do swojego pulpitu nawigacyjnego, niektóre kraje wykorzystały i opublikowały te informacje na swoich stronach internetowych, a następnie JHU potwierdził swoje wpisy, porównując ich liczby z tymi na oficjalnych stronach rządowych. Jeśli tak się stało, to jest to rozumowanie cyrkularne w najlepszym wydaniu. Niestety, nie ma sposobu, aby udowodnić, czy tak się stało, czy nie. Tak czy inaczej, wciąż zastanawiamy się, z jakich źródeł korzystał JHU.
Automatyczne aktualizacje
Niezależnie od źródeł, ręczne aktualizacje zostały wkrótce zakończone na rzecz automatyzacji:
„Ręczny proces raportowania stał się niezrównoważony; dlatego 1 lutego 2020 r. przyjęliśmy półautomatyczną strategię żywego strumienia danych”. [1]
Słowo „niezrównoważony” sprawia, że brzmi to tak, jakby byli zasypywani przypadkami Covid. Rzeczywiste fakty to obalają. Według raportów WHO w tym dniu tylko 19 krajów zgłosiło przypadki[24]. Mogło to obejmować od 80 do 100 zgłoszeń pierwszego lutego. Nie jest wcale jasne, w jaki sposób tak niewielka liczba zgłoszeń została uznana za niezrównoważoną.
Artykuł w Lancet twierdzi, że ręczne aktualizacje zostały najpierw potwierdzone przez odpowiednie organy służby zdrowia. Z drugiej strony nic nie mówi się o tym, czy zautomatyzowane dane wejściowe zostały kiedykolwiek potwierdzone.
Co więcej, czy w ogóle możliwe jest zautomatyzowanie gromadzenia danych w wielu witrynach internetowych z rosnącej listy krajów, skoro każda witryna używa różnych formatów do wyświetlania swoich danych? Pytanie to jest szczególnie ważne, biorąc pod uwagę, jak często formaty te były zmieniane podczas Covid. Rzeczywiście, jak stwierdziła jedna z grup badawczych, jeszcze w maju 2021 r. nadal nie było „standardów” raportowania danych Covid[17]. Jak zatem poradził sobie mały zespół JHU, skoro sam ostatecznie przyznał się do wszystkich tych problemów? [16]
Bariery językowe
Dwie z trzech osób zaangażowanych w projektowanie pulpitu nawigacyjnego JHU pochodziło z Chin, a trzecia była Amerykaninem. Umożliwiłoby im to czytanie chińskich raportów publikowanych na stronie DXY. Jednak nie każdy kraj na świecie publikuje dane w języku chińskim lub angielskim. Trudności w wyodrębnianiu danych ze stron internetowych w językach obcych są znaczne, nawet przy użyciu zautomatyzowanych narzędzi tłumaczeniowych. Zautomatyzowanie tego globalnie jest prawie niewyobrażalne. Skrobanie Internetu jest prawie niemożliwe, gdy przeszukiwane strony są w języku nieznanym badaczowi. Wyzwania tego rodzaju są powszechnie doświadczane przez każdego, kto prowadzi globalne badania, w wyniku czego badacze często ograniczają się do krajów, które używają znanego im języka. Jak zatem poradził sobie zespół JHU?
Pierwszy na starcie
Pulpit nawigacyjny JHU był prawie zawsze pierwszą stroną internetową, która zgłosiła pierwszy przypadek Covid w danej lokalizacji. Gardner twierdzi, że:
„dashboard jest szczególnie skuteczny w wychwytywaniu czasu pierwszego zgłoszonego przypadku COVID-19 w nowych krajach lub regionach… Z wyjątkiem Australii, Hongkongu i Włoch, CSSE na Johns Hopkins University zgłosił nowo zainfekowane kraje przed WHO, z Hongkongiem i Włochami zgłoszonymi w ciągu kilku godzin od odpowiedniego raportu sytuacyjnego WHO”[1].
W przeciwieństwie do tego, co sugeruje to stwierdzenie, pulpity nawigacyjne nie rejestrują tego typu informacji, robią to ludzie. Jak to możliwe, że mały zespół JHU zareagował tak szybko, aby znaleźć pierwszy nowy przypadek w prawie każdym kraju, zanim zrobił to ktokolwiek inny? Czy to tylko zbieg okoliczności, że Gardner niedawno opracowała model, który wykorzystywał wzorce podróży lotniczych, aby dokładnie to przewidzieć? Pisząc o tym modelu, powiedziała: „model zapewnia oczekiwaną liczbę (100) importowanych przypadków przybywających na każde lotnisko na całym świecie”[25].
Czy ten model był tak dokładny, że pomógł JHU w znalezieniu każdego pierwszego nowego przypadku? Biorąc pod uwagę, jak niedokładny był ten model, taki scenariusz jest wysoce nieprawdopodobny: ten sam model przewidywał liczbę przypadków w Chinach, która była pięciokrotnie wyższa niż zgłaszana. Pomimo tego rażącego problemu z jej modelem, Gardner nadal uważała, że jest on dokładniejszy niż raporty oparte na faktach:
„Uważamy, że rzeczywista liczba przypadków 2019-nCoV w Chinach kontynentalnych jest prawdopodobnie znacznie wyższa niż ta zgłoszona do tej pory. W szczególności szacujemy, że do końca stycznia w Chinach kontynentalnych wystąpi około 58 000 skumulowanych przypadków 2019-nCoV (na dzień 31 stycznia zgłoszonych przypadków jest blisko 12 000)”.
Czy nie jest zatem możliwe, że Gardner uważała również, że jej przewidywania dotyczące tego, kiedy i gdzie powinny wystąpić pierwsze przypadki, były również dokładniejsze niż to, co zgłaszał jakikolwiek kraj? Czy JHU zgłaszał nowe przypadki na swojej tablicy rozdzielczej w oparciu o swoje modele? Czy dlatego powiedziała, że ” dashboard był szczególnie skuteczny w wychwytywaniu…”? Jeśli tak, to czy inne kraje i WHO uwierzyły w to, co zgłosiła JHU, a następnie same to zgłosiły?
Modelowanie komputerowe jako główne źródło danych
Jedyną odpowiedzią, która zapewnia racjonalne wyjaśnienie wszystkich zadanych do tej pory pytań, jest to, że tablica rozdzielcza JHU była oparta na symulacjach komputerowych, a nie na danych obserwacyjnych. Wydaje się również, że od czasu do czasu zespół JHU uzyskiwał dane empiryczne, które były następnie wykorzystywane do dostosowywania i „korygowania” danych wyjściowych z ich modeli[26, 27]. Powody, dla których jest to najbardziej prawdopodobna odpowiedź, są następujące:
- Rządy nie są w stanie dostarczać danych w czasie rzeczywistym
- Wyodrębnienie danych z witryn mediów informacyjnych w językach obcych jest zbyt trudne.
- Wpisy na tablicy rozdzielczej zostały zautomatyzowane
- Nie istniał skuteczny sposób na usunięcie duplikatów danych uzyskanych ze źródeł wiadomości.
- Pulpit nawigacyjny był aktualizowany w krótkich odstępach czasu (15 minut lub co godzinę).
- Źródła obejmują Worldometer, stronę specjalizującą się w symulacjach komputerowych.
- Źródła obejmują również „bezpośrednią komunikację z dashboardem”, która mogła obejmować dane z symulacji komputerowej.
- Nie wiadomo, czy zautomatyzowane wpisy zostały w jakikolwiek sposób potwierdzone.
- Pulpit nawigacyjny został zaprojektowany w celu dostarczania danych organom służby zdrowia.
- Władze zdrowotne ufały, że dane JHU są dokładne.
- Repozytorium zawiera wiele zrzutów danych w celu ich „poprawienia”.
- Pulpit nawigacyjny informował o pierwszych nowych przypadkach w danym kraju, zanim zrobił to ktokolwiek inny.
Dowody na wykorzystanie modelowania komputerowego
W dniu 4 marca 2024 r. wysłałem wiadomość e-mail do Lauren Gardner (głównej autorki projektu tablicy rozdzielczej JHU) z pytaniem, czy w którymkolwiek momencie wykorzystano modele komputerowe na potrzeby dashboardu i czy były to modele dostępne. Niestety do dnia dzisiejszego nie otrzymaliśmy żadnej odpowiedzi.
Ze względu na brak ustnego potwierdzenia i znalezienie jak dotąd jedynie poszlak, konieczne było dalsze poszukiwanie być może lepszych dowodów na to, czy JHU korzystał z modeli komputerowych w celu uzyskania danych. Nic dziwnego, że dowody istnieją. Na przykład 13 marca 2020 r. profesor Lauren Gardner przemawiała na przesłuchaniu kongresowym na Kapitolu, aby wyjaśnić działanie tablicy informacyjnej. Podczas prezentacji wyraźnie wspomniała o „wysiłkach modelowania, które podejmujemy za kulisami”[10].
Ponadto na stronie internetowej JHU czytamy:
„Gardner jest specjalistą w modelowaniu ryzyka chorób zakaźnych, w tym COVID-19…. Gardner kieruje wysiłkami w zakresie modelowania COVID-19 we współpracy z amerykańskimi miastami w celu opracowania niestandardowych modeli szacowania ryzyka COVID-19 na poziomie lokalnym”. [28]
Kiedy te dwa cytaty zostaną połączone z faktem, że Gardner była tak zajęta zarządzaniem pulpitem nawigacyjnym na początku 2020 r., że nie miała czasu na nic innego, jest pewne, że prace modelarskie dotyczyły pulpitu nawigacyjnego. Rzeczywiście, jak wskazano w jednym z artykułów, „pracując przez całą dobę przez 10 tygodni z rzędu, byli tak pochłonięci konserwacją pulpitu nawigacyjnego, że mieli niewiele czasu na analizę danych, które faktycznie pokazuje”[6].
Warto również zauważyć, że w 2019 roku Gardner opracowała „nowatorskie ramy modelowania matematycznego” do szacowania epidemii wirusa, model, który miał zostać „skalibrowany przy użyciu historycznych danych dotyczących epidemii”[29].
Co więcej, strona internetowa Centrum Nauki i Inżynierii Systemów JHU stwierdza, że modelowanie jest jednym z podstawowych filarów ich wydziału. Wydział CSSE definiuje się następującymi słowami: „Nauka o systemach to podejście do modelowania, które obejmuje dynamiczną interakcję komponentów inżynieryjnych, ludzkich i naturalnych w czasie i przestrzeni”[30].

Laboratorium Fizyki Stosowanej(APL) JHU, Od lewej:
Evan Bolt, Ryan Lau, Beatrice Garcia, Aaron Katz i Tim Ng przeglądają dane z pulpitu nawigacyjnego w APL’s LIVE Lab
Źródło: JHU APL https://www.jhuapl.edu/news/news-releases/210426-JHU-COVID-dashboard-oral-history
Dlatego też, opierając się na fakcie, że Gardner jest ekspertem w modelowaniu chorób, jest przyzwyczajona do kalibracji modeli za pomocą danych empirycznych, była aktywnie zaangażowana w opracowywanie modeli dla Covid, udokumentowała, że jej modele są dokładniejsze niż oficjalnie zgłoszone liczby, a jej wydział uważa modelowanie za fundamentalne dla podejścia do każdego problemu, należy przyjąć za pewnik, że modele komputerowe były wykorzystywane jako podstawowe źródło danych. Innymi słowy, o ile nie istnieją mocne dowody przeciwne, pewne jest, że zespół JHU używał modeli komputerowych do generowania liczby przypadków i zgonów. Nie znaleziono jednak żadnych bezpośrednich dowodów.
W zgodzie z tymi odczuciami, ankieta przeprowadzona przez Jesse Pietza i in. wśród 25 różnych pulpitów nawigacyjnych Covid wyraźnie stwierdza, że pulpit nawigacyjny JHU wykorzystywał model epidemiologiczny SIRD (Susceptible, Infected, Recovered, Deceased) w 2020 r. do symulacji rozprzestrzeniania się Covid[31].
Wreszcie, w listopadzie 2020 r. opublikowano interesujący wątek na Twitterze, który dostarcza dowodów na to, że Ensheng Dong (student, który zbudował dashboard) przesyłał dane do repozytorium JHU z danymi utworzonymi za pomocą modelowania komputerowego[32]. (Chociaż żałujemy, że znaczenie tego wątku umknęło naszej uwadze przez tak długi czas, przyznajemy, że jego odkrycie stanowiło istotną część impulsu do badań, które doprowadziły do powstania tego artykułu).
W sierpniu 2022 r. Ensheng Dong i in. opublikowali przegląd swojego pulpitu nawigacyjnego, w którym omówiono niektóre wyciągnięte wnioski i wyzwania napotkane po drodze. Autorzy stwierdzili: „Zgodnie z naszym zobowiązaniem do udostępniania otwartych danych, dane wyświetlane na pulpicie nawigacyjnym pochodzą wyłącznie z publicznie dostępnych źródeł”[16]. A nieco dalej dodają: „tablica opierała się w całości na publicznie dostępnych danych”. Czy oznacza to, że tablica wykorzystywała wyłącznie dane empiryczne oparte na faktach? Niekoniecznie. Worldometer to „publicznie dostępne źródło”, które prawie na pewno opierało się na modelach komputerowych. Co więcej, niektóre rządy wykorzystały modele komputerowe do oszacowania, ile osób zachoruje lub umrze z powodu Covid. Dane wyjściowe z tych modeli były również publicznie dostępne. I nie jest nierozsądne sądzić, że niektóre organy służby zdrowia otrzymywały swoje liczby bezpośrednio z modeli JHU. Na uwagę zasługuje fakt, że nie twierdzą oni, że korzystali wyłącznie z danych empirycznych lub obserwacyjnych.

źródło: APL JHU https://www.jhuapl.edu/news/news-releases/210512-2020-Annual-APL-Achievement-Awards
Rządowa nagroda za wynalazek Laura Asher, Evan Bolt, Beatrice Garcia, Tamara Goyea, Aaron Katz, Ryan Lau, Tim Ng, Sarah Prata, Jeremy Ratcliff i Miles Stewart za gromadzenie danych, korektę błędów i platformy modelowania dla pandemii COVID-19. Naukowcy z APL zapewnili możliwości gromadzenia i zarządzania danymi w Centrum Zasobów Koronawirusa Uniwersytetu Johnsa Hopkinsa, które zostało wyróżnione na liście "Najlepszych wynalazków 2020 roku" magazynu Time. Przy wsparciu adiunkt Lauren Gardner z Johns Hopkins Whiting School of Engineering, która stworzyła pulpit nawigacyjny, oraz we współpracy z kolegami z JHU Sheridan Library, APL stworzono zautomatyzowany system danych, który umożliwia dokładną i terminową analizę danych zdrowotnych.
Modele komputerowe zostały wykorzystane w wielu krajach do oszacowania przypadków Covid i zgonów [33, 34]. Niezależnie od tego, jak wadliwe były te modele (a były strasznie wadliwe[35]), zawsze rozumiano, że były to tylko modele[36]. Z drugiej strony pulpit nawigacyjny JHU twierdził, że dostarcza dane w czasie rzeczywistym dotyczące rzeczywistych przypadków Covid i zgonów. Dowody zdecydowanie sugerują inaczej.
Mylenie danych
Istnieje wiele problemów, które naturalnie pojawią się, jeśli szanowany dashboard będzie miał rzekomo udostępniać dane empiryczne odpowiednie do wykorzystania przez organy służby zdrowia, ale dane bazowe są w rzeczywistości generowane przez modele komputerowe. Problemy te będą występować nawet wtedy, gdy dane zostaną „potwierdzone” i zaktualizowane o dane z oficjalnych stron rządowych.
Kilka godnych uwagi problemów, które się pojawią to:
- Niektóre kraje, wiedząc, że nie są w stanie uzyskać danych w czasie rzeczywistym, będą skłonne zaufać tablicy rozdzielczej i wykorzystać jej liczby do własnych celów. JHU następnie „potwierdza” swoje własne szacunki w stosunku do „oficjalnych” liczb. Ponieważ oficjalne liczby opierały się przede wszystkim na własnych szacunkach, błąd zostaje potwierdzony i ani dane JHU, ani oficjalne dane kraju nie są poprawne. W rezultacie liczby Covid w niektórych krajach będą tak samo błędne, jak modele komputerowe.
- Inne kraje będą całkowicie polegać na własnych danych. Kiedy JHU „potwierdzi” swoje szacunki, dane JHU zostaną skorygowane. W tym scenariuszu dane będą tak poprawne, jak pozwalają na to testy i diagnostyka laboratoryjna lub jak pozwalają na to dane z tych krajów.
- W wyniku powyższego dwa sąsiadujące kraje mogą mieć znacznie różne wskaźniki przypadków Covid i zgonów, nie dlatego, że Covid zachowywał się inaczej w obu krajach, ale dlatego, że jeden kraj zaakceptował dane JHU jako wiarygodne, a drugi nie. Ostatecznym rezultatem będzie to, że niemożliwe będzie porównanie statystyk Covid między krajami.
- Ponieważ dane JHU zostały podzielone na miasta w niektórych regionach świata, niektóre miasta mogły zaakceptować dane JHU, podczas gdy inne nie. W rezultacie statystyki Covid mogą być oparte na danych empirycznych w jednym mieście i modelach w innym. Uniemożliwi to porównanie jednego miasta z jego sąsiadem.
- W krajach, w których JHU dostarczyło dane na poziomie miasta, ponieważ niektóre miasta wykorzystały dane JHU jako własne, a inne nie, zagregowane wartości dla każdej prowincji lub stanu mogą być bez znaczenia.
- Efekt netto polegający na tym, że niektóre regiony akceptują dane JHU, a inne nie, zarówno na poziomie miasta, stanu, jak i kraju, będzie oznaczał, że wszelkie algorytmy komputerowe stosowane w modelach JHU będą widoczne dla niektórych lokalizacji geograficznych, ale nie dla innych. W rezultacie w niektórych miejscach dane będą pasować do modelu SIRD, podczas gdy w innych nie. To sprawi, że badania epidemiologiczne będą beznadziejnie zagmatwane.
Wszystkie wyżej wymienione problemy były głównymi aspektami wielu dyskusji wokół Covid – nie tylko tych, w które sami się angażowaliśmy i o których pisaliśmy, ale także tych, o których czytaliśmy lub których jesteśmy świadomi. Na przykład, badając Włochy, odkryliśmy, że zgony z powodu Covid są zgodne z granicami regionalnymi, a nie z tym, czego można by się spodziewać po epidemii nowego wirusa[37]. Podczas badania Nowego Jorku odkryliśmy, że to, co podobno wydarzyło się w tym mieście, nie wydarzyło się w innych dużych miastach w USA[38]. Badając wzorce śmiertelności na całym świecie, odkryliśmy, że Covid „szanował” granice regionalne w nieoczekiwany sposób[39, 40]. Dlatego rzeczywiste problemy, które pojawiły się podczas badania danych Covid, są zgodne z rodzajem problemów, których można by się spodziewać, gdyby tablica rozdzielcza JHU była oparta na symulacjach komputerowych uzupełnionych danymi obserwacyjnymi.
Przykładem tego, jak poważna może stać się sytuacja, w której informacje są uważane za oparte na prawdziwych faktach, chociaż opierają się na modelu komputerowym, jest zniknięcie lotu MH370 w 2014 roku. Oprogramowanie używane przez Malaysia Airlines do śledzenia samolotów doprowadziło ich do przekonania, że zaginiony samolot znajdował się nad Kambodżą. Jednak później odkryto, że „śledzenie lotu” opiera się na [symulowanej komputerowo] projekcji i nie można na nim polegać przy rzeczywistym pozycjonowaniu lub wyszukiwaniu”[41]. Samolot nie znajdował się nigdzie w pobliżu Kambodży, a opóźnienie spowodowane tym nieporozumieniem wystarczyło, aby samolot został utracony[42].
Przykład: Nowy Jork
Wreszcie, kończymy dyskusję na temat pulpitu nawigacyjnego JHU, analizując Nowy Jork (NYC) jako studium przypadku, aby wizualnie zademonstrować niektóre z tych kwestii. Na pierwszym wykresie poniżej, dzienne zgony z powodu Covid są wykreślane przy użyciu danych uzyskanych z dwóch różnych źródeł: NYC Health (niebieska linia) i JHU dashboard (czerwona linia). Trzecia linia (zielona) jest po prostu wynikiem pomnożenia dziennych wartości JHU przez 4/3. Powód tej zielonej linii wyjaśniono poniżej. Wykres obejmuje wszystkie zgłoszone zgony z powodu Covid w Nowym Jorku do 17 maja 2020 r.

Rysunek 1: Codzienne zgony z powodu Covid w Nowym Jorku z dwóch różnych źródeł: NYC Health (niebieska linia) i JHU dashboard (czerwona linia). Oba źródła podają „dzień zgłoszenia”, a nie „dzień zgonu”. Dane zostały pobrane w marcu 2024 roku.
Zielona linia to dzienna wartość JHU pomnożona przez 4/3.
Źródło: NYC Health: https://github.com/nychealth/coronavirus-data/blob/master/trends/deaths-by-day.csv
Źródło: Pulpit nawigacyjny JHU:https://github.com/CSSEGISandData/COVID-19/blob/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_US.csv
Powodem, dla którego 17 maja 2020 r. został wybrany jako data graniczna dla tego wykresu, jest fakt, że NYC Health (NYCH) zmienił kilka kluczowych aspektów swoich metod raportowania w tym dniu, powodując znaczne zakłócenia w trendach JHU. Należy również zauważyć, że dane wykorzystane na powyższym wykresie nie zostały wprowadzone do odpowiednich repozytoriów Github w przedstawionym dniu. Dane NYCH zostały po raz pierwszy wprowadzone do repozytorium 22 grudnia 2020 r., po czym były wielokrotnie korygowane w ciągu następnych trzech lat. Dane JHU były wprowadzane codziennie do 17 maja, a następnie ponownie korygowane 1 lipca, 31 sierpnia i 1 września. Poza tym, że we wrześniu. Jeden wpis przez JHU został dokonany w celu dystrybucji zgonów w Nowym Jorku według dzielnic, nie jesteśmy świadomi żadnych wyjaśnień dotyczących innych korekt[43].
Ogólnie rzecz biorąc, zarówno NYCH, jak i JHU uwzględniały to, co nazywały „prawdopodobnymi zgonami” w swoich dziennych liczbach. Ponieważ śledzili te kwoty osobno i codziennie, zdecydowaliśmy się uwzględnić je w dziennych wartościach NYCH (niebieska linia), ale nie w przypadku JHU (czerwona linia). W ten sposób różnica między niebieską i czerwoną linią na powyższym wykresie wynika z „prawdopodobnych zgonów”. [43]
Podobieństwa między niebieską i zieloną linią stanowią niemal niepodważalny dowód na to, że liczby „prawdopodobnych zgonów” zostały sztucznie wygenerowane na komputerze. Przy odrobinie wysiłku udało mi się znaleźć stosunkowo proste równanie, które sprawia, że dopasowanie między tymi dwiema liniami jest prawie idealne. Pozostawiamy jednak NYCH lub JHU podzielenie się wzorem, którego użyli do wygenerowania swoich „prawdopodobnych zgonów”.
Następnie wykreślamy dane dotyczące zgonów Covid (w tym „prawdopodobnych zgonów”) tylko z NYCH (ryc. 2 poniżej). Gładkość krzywej jest niezwykła i prawie na pewno odzwierciedla wykorzystanie modelu epidemiologicznego SIRD jako podstawowego źródła danych. Oczywiście, ponieważ krzywa JHU ma identyczny kształt (tylko z mniejszymi liczbami), ona również odzwierciedla model SIRD. Ponieważ ustaliliśmy już, że istnieje proste równanie dla „prawdopodobnych zgonów”, jest to dość przekonujący dowód na to, że modele zostały użyte dla wszystkich danych: potwierdzonych, prawdopodobnych i całkowitych.
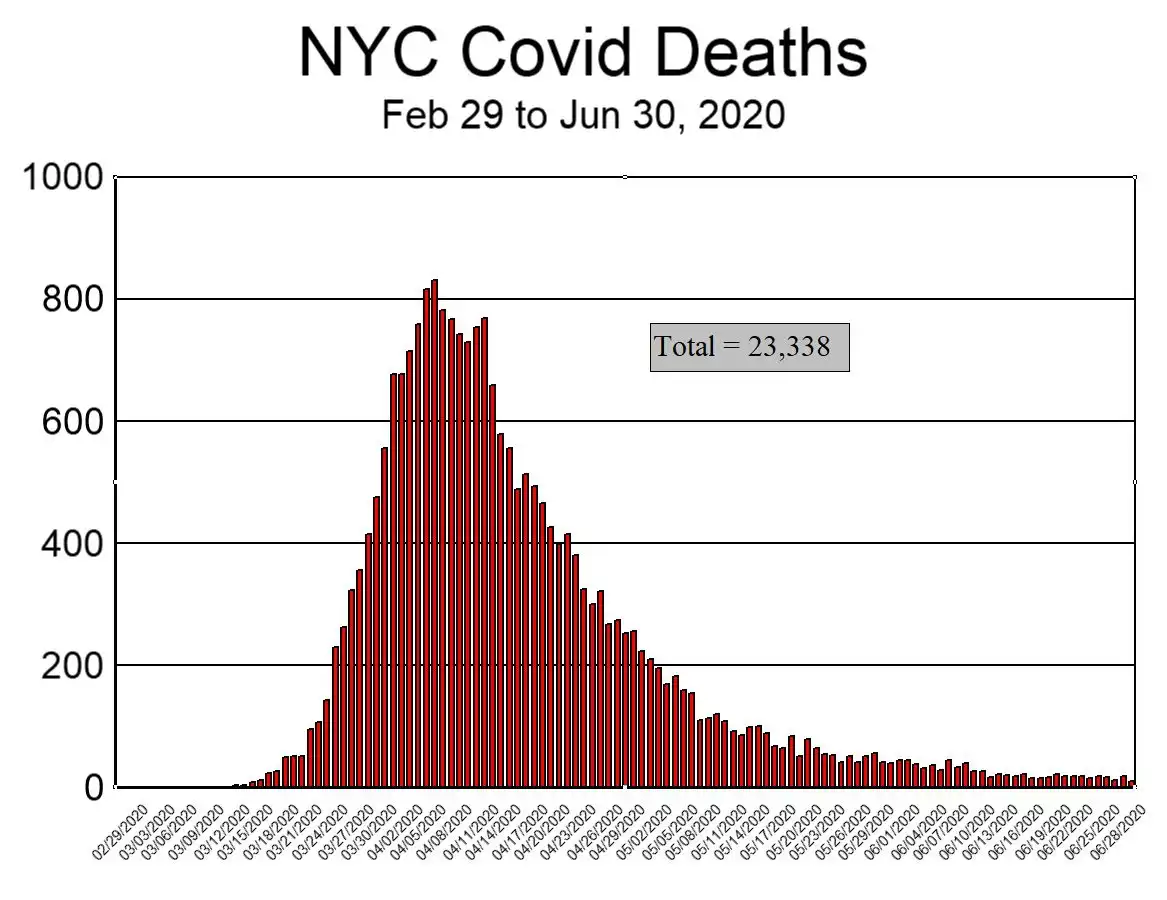
Rysunek 2: Zgony z powodu COVID-19 w Nowym Jorku.
Źródło: NYC Health: https://github.com/nychealth/coronavirus-data/blob/master/trends/deaths-by-day.csv
Aby podkreślić ten ostatni punkt i dla celów porównawczych, następnie wykreślamy wykres zgonów z powodu Covid w prowincji Hubei w ciągu pierwszych trzech miesięcy 2020 r. (Rysunek 3 poniżej). Pomimo faktu, że populacja prowincji Hubei (58 milionów) jest siedmiokrotnie większa niż w Nowym Jorku (8,3 miliona), liczba zgonów w Hubei (szczyt: 147, suma: 3164) była znacznie mniejsza niż w Nowym Jorku (szczyt: 831, suma: 23 338). Aby te liczby były prawidłowe, oznaczałoby to, że to, co wydarzyło się w Nowym Jorku, było 51 razy gorsze niż to, co wydarzyło się w prowincji, z której rzekomo pochodzi Covid. Taki scenariusz jest tak nieprawdopodobny, że graniczy z niedorzecznością i potwierdza tezę, że dane z Nowego Jorku nie były oparte na zaobserwowanych faktach.

Rysunek 3: Zgony z powodu Covid w Wuhan w Chinach, według dnia zgłoszenia, od stycznia do marca 2020 r. Dwudniową średnią kroczącą zastosowano dla 12 i 13 lutego, 21 i 22 lutego oraz 23 i 24 lutego. Miało to na celu zachowanie obserwowalnego kształtu wykresu. Pierwotnie liczba zgłoszonych zgonów wynosiła zero w dniach 12, 21 i 23 lutego; a szczyt wynosił 242 w dniu 13 lutego.
Źródło: Dane JHU CSSE COVID-19. https://github.com/CSSEGISandData/COVID-19
Zauważono również, że wykres dla prowincji Hubei (rys. 3) jest bardziej zgodny z tym, jak zwykle wyglądają dane empiryczne (postrzępiony), podczas gdy wykres dla NYC (rys. 2) przypomina to, co wygenerowałby model komputerowy (gładki).
Wcześniej wykazaliśmy, że niemożliwe jest, aby 23 338 osób zmarło na Covid w Nowym Jorku wiosną 2020 roku[44]. Wykazaliśmy również, że dane dotyczące śmiertelności w Nowym Jorku są wątpliwe[38]. W oparciu o obecną dyskusję argumentujemy teraz, że najbardziej realnym wyjaśnieniem błędnych danych jest to, że algorytm komputerowy (oparty na modelu epidemiologicznym) został połączony z niewłaściwą pętlą sprzężenia zwrotnego między JHU i NYCH. Wszystko to sugeruje, i to raczej mocno, że liczby zgonów z powodu Covid dla Nowego Jorku zostały wymyślone na kalkulatorze, a nie policzone w kostnicy. Zachęcamy NYCH lub JHU do wyjaśnienia, dlaczego i w jaki sposób liczby te należy interpretować inaczej, oraz do przedstawienia aktów zgonu zmarłych jako dowodu.
Oczywiście, jeśli liczba zgonów z powodu Covid w Nowym Jorku była oparta na modelu komputerowym, wynika z tego, że mieszkańcy Nowego Jorku zostali poddani trzem miesiącom niepotrzebnego terroru na początku 2020 r., kiedy powiedziano im, że tysiące ich sąsiadów ginie z powodu Covid, podczas gdy nikt nie miał (lub jeszcze nie ma) pojęcia, ile osób faktycznie umiera. Jest zatem całkiem możliwe, że wiosną 2020 r. w Nowym Jorku nie wydarzyło się nic niezwykłego (podobnie jak nic niezwykłego nie wydarzyło się w Chinach[45]), a średni wzrost liczby połączeń 911 o 24%[46] w tym okresie, wraz z niewytłumaczalnym i niepokojącym wzrostem liczby zatrzymań akcji serca[47] nie był spowodowany Covid, ale strachem wywołanym przez media[48].
Wnioski
Pulpit nawigacyjny JHU został „opracowany w celu zapewnienia naukowcom, organom zdrowia publicznego i ogółowi społeczeństwa przyjaznego dla użytkownika narzędzia do śledzenia epidemii w miarę jej rozwoju”. Pomijając fakt, że śledzenie jakiejkolwiek choroby w czasie rzeczywistym jest funkcjonalnie niemożliwe i niezależnie od tego, że nic szczególnego się nie „rozwijało”, gdy ją opracowywano, wszystkie dowody wskazują na to, że udało im się stworzyć pulpit nawigacyjny Covid za pomocą modeli komputerowych, które od czasu do czasu były „korygowane” danymi uzyskanymi z oficjalnych rządowych stron internetowych. Mieszając dane z modeli komputerowych z danymi z obserwacji, jednocześnie twierdząc, że „w całości polegali na publicznie dostępnych danych”, pomylili dane tak bardzo, że stały się one bez znaczenia. W rezultacie baza danych JHU Covid jest i była tak niewiarygodna, że nigdy nie powinna być używana do określania przypadków Covid lub zgonów.
Jakkolwiek zaskakująco może brzmieć ten wniosek, jest to w zasadzie to, co Aaron Katz (przełożony w zespole programistów JHU) powiedział cztery lata temu:
„Za dziesięć lat zobaczymy wszystkie raporty i retrospektywy, które powiedzą nam dokładnie, co się stało i gdzie….[Ale na razie] staramy się rozwiązać ten problem świadomości sytuacyjnej w chwili obecnej”[11].
Przynajmniej jego słowa informują nas, że uzyskanie dokładnych danych na temat konkretnej choroby zajmuje zwykle dziesięć lat. W najgorszym przypadku cytat ten zapewnia nas, że tablica rozdzielcza JHU była niewiarygodna, że zaufanie pokładane w danych było całkowicie błędne, a tablica rozdzielcza JHU spowodowała wiele błędnych wniosków na temat Covid.
W świetle tych wszystkich faktów i obserwacji:
- Wzywamy rządy i urzędy statystyczne na całym świecie do powrotu do dawnego powolnego, ale dokładnego procesu gromadzenia wiarygodnych danych za pośrednictwem normalnych kanałów,
- Zachęcamy badaczy medycznych, aby oparli się pokusie korzystania z danych Covid z repozytorium JHU i zamiast tego poczekali, aż wiarygodne dane staną się dostępne,
- Zwracamy się do Uniwersytetu Johna Hopkinsa o pełną otwartość i przejrzystość w zakresie kodu komputerowego, modeli, źródeł i procedur wykorzystywanych w ich pulpicie nawigacyjnym,
- Wzywamy Nowy Jork do rozpoczęcia przejrzystego dochodzenia w sprawie tego, czy i w jaki sposób ich dane zostały zniekształcone przez modele komputerowe,
- Wzywamy opinię publiczną do bardziej krytycznego podejścia do wszelkich twierdzeń dotyczących globalnych statystyk choroby „w czasie rzeczywistym”.
autor:
Thomas Verduyn
Autor jest wdzięczny za nieocenioną pomoc udzieloną przez współpracowników i autorów tego artykułu, którzy pragną pozostać bezimienni.
źródło:
https://pandauncut.substack.com/p/the-dashboard-that-ruled-the-world
Thomas Verduyn, BASc – uzyskał tytuł licencjata z wyróżnieniem w dziedzinie inżynierii lotniczej i kosmicznej. Ma szeroki zakres doświadczeń zawodowych, w tym doradztwo komputerowe, budownictwo, transport, księgowość i przedsiębiorczość. Jest zapalonym czytelnikiem wielu różnych dziedzin. Opublikował wiele książek, jest żywo zainteresowany zdrowiem i pasjonuje się poznawaniem Boga.
Dariusz Galczak
Hej jestem Dariusz Galczak współtwórca AlterShot. Od marca 2020 wyszukuję i tłumaczę teksty o zachodzących wokół nas przemianach, także o „wiadomej sprawie”, by dać szerszą perspektywę tam gdzie jej brakuje. Od lipca 2020, tworzę też filmy i relację głównie z konferencji. Mimo, że jak wielu „nowa sytuacja” postawiła mnie w nowej roli, to staram się współpracować z profesjonalistami i stale rozwijać umiejętności i warsztat.