„Aby przywrócić zaufanie społeczeństwa do nauki o szczepionkach, konieczne jest przeprowadzenie gruntownej czystki”. ACIP rozwiązany.


„Aby przywrócić zaufanie społeczeństwa do nauki o szczepionkach, konieczne jest przeprowadzenie gruntownej czystki”. ACIP rozwiązany.
| ROBERT W MALONE MD, MS JUN 9 |

Medical freedom became a rallying point for groups across the political spectrum, especially those opposing government mandates and expressing broader distrust of federal health agencies during COVID-19. The medical freedom movement is not just about healthcare; it is about civil liberties, government authority, and the role of science in policymaking.
Before COVID-19, the term anti-vaxxer was targeted towards people who are against all vaccines. Targeted as a way to delegitimize their complaints and observations, by personally delegitimizing them. More PsyWar. But times have changed. The defamatory attack has become a badge of honor.
Various news articles state that 35–45% of Americans, including myself, find vaccine mandates unacceptable. The government and corporate media have defined this group of people as being anti-vaxxers. Some people still believe that the term anti-vaxxer is a pejorative. I do not – I view it as high praise.
I like to think of the people who fit this definition of „anti-vaxxer” as representing a subset of the freedom fighters in our culture. People who advocate against mandates are working to end the madness of the vaccine mania that has swept public health and government. They (we) are working to protect our rights under the Constitution.
The term „anti-vaxxer” it is not a slur but rather it is a compliment.
Embrace it. Own it. And be proud to be a part of this fight.
Malone News is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Which brings me to the next phrase that I hear bantered about:
The term MAHA, an acronym for „Make America Healthy Again,” originated as a political slogan and movement in the United States in mid-2024. Robert F. Kennedy Jr. first introduced it during his independent campaign run for U.S. President.
After suspending his campaign in August 2024 and endorsing Donald Trump, Kennedy continued to champion the MAHA agenda, which focuses on public health, reducing chronic illness, promoting healthier lifestyles, and addressing corruption in the food and pharmaceutical industries.
As I don’t want to write what “I think” MAHA is, I went to CHAT-GPT3 for a definition. Below is what it provided in response to my query concerning what MAHA stands for:
“During Robert F. Kennedy Jr.’s independent presidential campaign—before Donald Trump’s election—the term MAHA („Make America Healthy Again”) stood for a broad, populist health reform agenda centered on several key themes:

While Kennedy’s campaign version of MAHA focused heavily on government accountability and “health freedom,” after the election, the official agenda developed by the all-of-government MAHA Commission, under an executive order from the President, placed greater emphasis on federal intervention to reshape food, health, and environmental systems.
But MAHA, as defined by the person who coined the phrase, was never about immediately banning the mRNA or all vaccines. That is yet another false, promoted narrative.
The press and the government have done an excellent job of portraying Kennedy as a “one-trick pony.” Someone who has been advocating on one issue only – the “anti-vaxxer” candidate. That is so laughable that it is hard to maintain a straight face when hearing or reading it.
But the truth is that the narrative of Kennedy being an activist who is for banning all vaccines, defined and promoted by corporate and political opponents, has stuck to him like “flies on s**t.” For this reason, I am providing a professional CV below (this again is AI generated – so whatever bias is included, it is not mine):
Professional CV: Secretary Robert F. Kennedy Jr.
Full Name: Robert Francis Kennedy Jr.
Date of Birth: January 17, 1954
Current Position: Secretary of the U.S. Department of Health and Human Services (HHS) (2025–present)
Political Affiliation: Former Democrat, Independent, Trump Administration Cabinet Member
Family: Son of Senator Robert F. Kennedy and Ethel Kennedy; nephew of President John F. Kennedy; married to Cheryl Hines; father of seven childrenEducation
- Harvard University – Bachelor’s Degree (1976)
- London School of Economics – Attended
- University of Virginia School of Law – Juris Doctor (1982)
- Pace University School of Law – Master’s Degree in Environmental Law (1987)
Professional Experience
Secretary of Health and Human Services, United States (2025–present)
- Leads the U.S. Department of Health and Human Services, overseeing public health policy, medical research, drug regulation, and health insurance programs with a $1.8 trillion budget.
- Appointed by President Donald Trump; confirmed by the Senate in February 2025.
- Chairs the „Make America Healthy Again” (MAHA) Commission, focusing on chronic disease, food safety, and pharmaceutical policy.
Presidential Candidate, U.S. Election (2024)
- Ran as a Democrat and then as an Independent before endorsing Donald Trump.
Founder & Chairman, Waterkeeper Alliance (1999–2020s)
- Established the world’s largest clean water advocacy group; served as longtime chairman and attorney.
- Led legal and policy campaigns to protect water resources globally.
Senior Attorney, Natural Resources Defense Council (NRDC) (1980s–2010s)
- Worked on landmark environmental litigation and advocacy.
- Adjunct Professor & Co-Director, Environmental Litigation Clinic, Pace University School of Law (1986–2018)
- Founded and supervised the clinic, training law students in environmental litigation and advocacy.
Assistant District Attorney, Manhattan (early 1980s)
- Began legal career prosecuting criminal cases.
Founder & Chairman, Children’s Health Defense
- Led organization focused on childhood chronic disease and environmental exposures; known for anti-vaccine advocacy.
Major Legal and Policy Achievements
- Led successful campaigns to restore the Hudson River, earning TIME Magazine’s “Hero for the Planet” honor.
- Negotiated the New York City watershed agreement, regarded as a global model for sustainable development.
- Won landmark environmental cases, including litigation against Monsanto (2018) and DuPont (2019).
- Represented Indigenous groups in treaty and environmental rights cases across the Americas”
Secretary Kennedy was born for this position as HHS Secretary and leader of the MAHA movement.
Why do I write about Kennedy’s accomplishments and feel the need to highlight his CV? Because Sec. Kennedy is not just about vaccine advocacy, he has been in the fight to stop chronic illnesses in children and adults traceable to environmental toxins throughout his entire career. This is a man who has been on a mission. Vaccines containing mercury in various forms are one of those toxins.
But the influential nattering nabobs of negativity from the medical freedom movement just won’t stop attacking him for what they arbitrarily define as his lack of progress in ending the mRNA vaccines. They don’t seem to understand that MAHA was always bigger than one segment of his MAHA agenda, even if it happens to be the segment that they are particularly passionate about.
When I go to Facebook or Instagram, what I view are millions of people who are 200% behind him and the full MAHA agenda. This is truly a movement to stop the epidemic of chronic disease, and it has bipartisan support. It is like none other, save for the „Ron Paul Revolution.” This term became the rallying cry for Ron Paul’s supporters during his 2008 and 2012 presidential campaigns, and encapsulates the grassroots, libertarian-leaning push for limited government, sound money, non-interventionist foreign policy, and expanded civil liberties. This took hold across college campuses, and that grass-roots campaign of over a decade ago continues to influence politicians like VP JD Vance and even President Donald Trump today.
As I wrote in my recent essay last week, Secretary Kennedy is now an employee of the United States government; he has to abide by the laws, rules, and regulations of his predecessors and his overseers – the US Congress and President Trump.
So, I am pretty shocked by the outrage against Kennedy, with many of his former friends and colleagues even calling for his outright resignation. Take Dr. Peter Breggin, for example – whose lengthy and frankly irrational tirade this week against Kennedy included the following:

…he should resign or be forced to resign. Allowing the Covid vaccines to be continued against older people is unconscionable, and so is their use in general. Beyond that, RFK Jr.’s promotion of methylene blue, MDMA, and psychedelics will vastly weaken the bodies, brains, and morality of Americans. There is no place for RFK Jr.’s perspectives on mRNA vaccines and psychoactive drugs in the Trump-led America First effort to preserve free will and personal sovereignty in the U.S. and the world.
…But in addition, he is also grossly undermining the Trump administration and further threatening the well-being of all our citizens
-Dr. Peter Breggin, on Substack
To which the Midwestern Doctor replied:
The most likely reason for this is that influencers now see this issue as a way to generate more clicks, likes, and followers. Just like Dr. Breggin spent a year of his life podcasting about how I am a mass murderer, a neo-nazi, and controlled opposition, this is a new way to generate followers.
Others claim that they represent “MAHA moms” – and say that Kennedy promised to ban the COVID-19 vaccines. Therefore, he has broken his promise to MAHA. An open letter circulating around the internet, states “Removal of the mRNA platform from the market is one of the main goals of the grassroots MAHA movement.” This is a lie. Banning all mRNA platform products was never part of the original MAHA platform. Why? Because Secretary Kennedy knew he would lose the support of the American people if he called for a ban on the mRNA vaccines at this time. Because the majority of people weren’t yet convinced of the risks. That his job would include gathering the data to convince the general public that the risks are real, that these products have damaged many, and that the risks exceed the benefits. That this would require more data.
In fact, during his presidential campaign, Robert F. Kennedy Jr. never explicitly promised to remove or ban COVID-19 vaccines from the market. However, he has consistently advocated for eliminating the COVID-19 vaccine from the CDC’s recommended immunization schedule for children and healthy pregnant women, which he has now done. This will set in motion the removal of the liability for these products and ultimately will make them unprofitable for pharmaceutical companies to produce.
Kennedy has argued that there was insufficient scientific justification for including the vaccine among routine childhood immunizations, citing the low risk of severe COVID-19 in healthy children and the shifting recommendations in other countries.
This is in complete harmony with his professional conduct as an attorney; he is a pragmatic leader who has to work within the system.
Change is coming. It isn’t as fast as many would like, but Secretary Kennedy is fighting more than one battle at a time.
So, I ask his detractors – those who once considered him a friend, rather than attacking him for doing precisely what he said he was going to do, how about leaning in to helping Make America Healthy Again?
Because Kennedy is right. Chronic disease is killing Americans, including American children. And we need to get to the bottom of this and then do something about it. Reflecting the all-of-government mandate, the MAHA commission report required many compromises between various constituencies. Calley Means fought long and hard to even get that modest text inserted into the document. He would have liked to have it be stronger, as would many including myself. But in politics, perfect is the enemy of the good.
You can’t always get what you want. But if you try, sometimes, you get what you need.
So, stop the infighting, please. We have work to do. Let’s get back to it.
https://gloria.tv/post/oZWJmZox6SGU1q2A9DwRq2hSU
„Pół godziny po przyjęciu do szpitala została potraktowana jako przypadek COVID-19 i natychmiast została podłączona do respiratora. O siódmej rano miała spalone, zwęglone płuca.
Lekarz, gówniarz, partacz, o siódmej rano mówi do mnie: 'Panie Olszański żona panu zmarła o godzinie siódmej’, nie było słowa 'przepraszam’, zabił moją żonę” – cytuje słowa wypowiedziane przez Olszańskiego w sądzie dziennik „Fakt”.
Przez cały listopad zmagałem się ze szpitalem w Warszawie, żeby pochować moją żonę, tak jak chciała do ziemi, bo była córką rolników.
Nie mogłem. Zaproponowali mi, że moją żonę można spopielić. Dowiedziałem się, że pogrzeb może być nawet bez mego udziału. Ona powiedziała mi kiedyś: 'nie waż się mnie spopielać, bo będę w nocy cię straszyć’ ...
Musiałem moją żonę spopielić jak psa. Nawet nie miałem prawa brać udziału w tej kremacji” – zdradził Olszański podczas jednej z rozpraw sądowych.
Nie mógł pogodzić się z przedwczesną śmiercią żony, która miała wpaść w śpiączkę cukrzycową.
| DR IGNACY NOWOPOLSKI JUN 8 |

Odzyskane urządzenia rzekomo zawierają komunikaty i dokumenty, które oskarżają Fauciego o organizowanie szkodliwych polityk, według Patela, choć szczegółowe informacje pozostają tajne. Śledztwo FBI, zintensyfikowane pod przewodnictwem Patela, ma na celu ujawnienie pełnego zakresu domniemanych nadużyć, a źródła twierdzą, że dowody mogą prowadzić do bezprecedensowych konsekwencji prawnych. Fauci nie odpowiedział publicznie na te oskarżenia.
Dailymail.co.uk podaje:
Patel powiedział, że śledczy od dawna mieli problemy ze zlokalizowaniem urządzeń, których Fauci używał, gdy był głównym doradcą medycznym Białego Domu — zapisów, które mogą rzucić światło na kluczowe decyzje dotyczące blokad, nakazów noszenia maseczek i powiązań między byłą agencją Fauciego a laboratorium w Wuhan, które jest kluczowe dla teorii wycieku laboratoryjnego.
W odcinku, w którym Patel dzielił się cygarem z Roganem i poruszał tematy o COVID-19 , ujawnił, że FBI odzyskało telefon i dyski twarde zaledwie kilka dni przed nagraniem wywiadu.
Nie jest jasne, kiedy dokładnie użyto telefonu i jak zweryfikowali, że należy on do Fauciego. Patel nie sprecyzował, w jaki sposób go przejęli ani co do tej pory wykazały „liczne dochodzenia” zespołu w sprawie pochodzenia Covid.
Patel nazwał odkrycie „zwycięstwem narodu amerykańskiego” i dodał, że jego zespół aktywnie analizuje zawartość urządzeń.
Patel powiedział: „Znaleźliśmy je [urządzenia], ale przynajmniej możemy powiedzieć Amerykanom, że ich szukaliśmy, ponieważ ważne jest, aby dowiedzieć się, czy ten facet kłamał?”
Czy celowo wprowadził świat w błąd i spowodował niezliczoną liczbę zgonów?
„Odpowiedzi te zawdzięczamy Amerykanom, a najlepszym dowodem jest zawsze dowód ludzi, którzy go stworzyli. Więc teraz pójdziemy i wykorzystamy te dyski twarde”.
„Znaleźliśmy go [telefon komórkowy], ale to nie koniec, wciąż szukamy i pracujemy nad tą sprawą”.
Patel nie sprecyzował, w jaki sposób jego zespół zdobył stary telefon ani w jaki sposób zweryfikowali, że należy on do Fauciego. Zazwyczaj do zajęcia telefonu komórkowego wymagany jest nakaz, nawet w przypadku urzędnika rządowego.
W chwili obecnej nie ma żadnych publicznie dostępnych nakazów aresztowania Fauciego.
Zarówno FBI, jak i CIA twierdzą, że wirus COVID najprawdopodobniej pochodzi z Instytutu Wirusologii w Wuhan w Chinach, który w latach poprzedzających pandemię przeprowadzał ryzykowne eksperymenty z koronawirusami.
Niektóre z tych eksperymentów finansowano z pieniędzy amerykańskich podatników za pośrednictwem dotacji przyznanych przez były wydział dr. Fauciego, Narodowy Instytut Alergii i Chorób Zakaźnych (NIAID).
Dr Fauci, niegdyś postrzegany jako „jedyny dorosły w pokoju” w obliczu chaotycznej i mylącej reakcji rządu na początkową epidemię w 2020 r., w ostatnich latach odczuł negatywne skutki utraty swojego olśniewającego wizerunku publicznego.
Zmieniał stanowisko w sprawie kluczowych informacji dotyczących bezpieczeństwa w związku z COVID-19, w tym dotyczących maseczek, i starał się uciszyć naukowców, których poglądy różniły się od poglądów głównego nurtu.
Z ujawnionych e-maili wynika, że na początku 2020 r. zlecił napisanie artykułu potępiającego tę teorię jako spisek, a następnie kilka tygodni później na konferencji prasowej w Białym Domu nagłośnił wyniki badania, nie ujawniając przy tym swojego udziału.
On i inni eksperci ds. zdrowia publicznego również publicznie odrzucili wyciek danych z laboratorium – dr Fauci powiedział w czerwcu 2021 r., że jest to „bardzo, bardzo, bardzo, bardzo odległa możliwość”.
Później okazało się, że jako szef NIAID, przewodniczył przyznawaniu grantów finansowanych przez podatników na badania nad wzmocnieniem skuteczności leczenia wirusa w WIV na wiele lat przed wybuchem pandemii.
Federalny organ nadzorczy stwierdził, że NIH „nie monitorował skutecznie” tych eksperymentów i nie sprawdzał, czy obejmowały one patogeny stwarzające ryzyko pandemii.
Dr Fauci prywatnie wyraził obawy, że wirus mógł być wynikiem wypadku podczas badań.
Inne agencje wywiadowcze na arenie międzynarodowej również poparły teorię wycieku z laboratorium.
Federalna Służba Wywiadowcza Niemiec (BND) przeprowadziła tajne dochodzenie w sprawie pochodzenia COVID-19, znane jako Projekt Saaremaa, podczas pandemii i w grudniu 2024 r. podzieliła się swoimi ustaleniami ze Stanami Zjednoczonymi.
Śledczy znaleźli nieopublikowane rozprawy z 2019 i 2020 r., w których rzekomo omawiano wpływ koronawirusów na organizm człowieka.
Ponadto odkryte materiały ujawniły, że chińscy naukowcy dysponowali „niezwykle obszerną wiedzą na temat rzekomo nowego wirusa, dostępną na niezwykle wczesnym etapie”.
Na podstawie materiałów znalezionych i przeanalizowanych przez agentów BND, wykorzystali oni „wskaźnik prawdopodobieństwa” do zmierzenia wiarygodności informacji, który określił teorię wycieku laboratoryjnego jako „prawdopodobną” z pewnością wynoszącą od 80 do 95 procent.
Robert Redfield, były dyrektor CDC w momencie wybuchu pandemii, oskarżył również amerykańskie i brytyjskie agencje zdrowia o bagatelizowanie obaw dotyczących potencjalnych wycieków danych z laboratoriów.
W rozmowie z DailyMail.com powiedział, że jest „w stu procentach” przekonany, że COVID-19 był wynikiem zakażenia naukowców podczas przeprowadzania ryzykownych eksperymentów mających na celu zwiększenie zakaźności wirusów nietoperzy w warunkach niskiego poziomu bezpieczeństwa biologicznego w laboratoriach w Wuhan.
Fauci zaprzeczył wszystkim oskarżeniom, że Covid został „zatuszowany” lub pochodzi z laboratorium. W 2024 r. powiedział komisji Izby Reprezentantów USA, że nie tłumił teorii wycieku z laboratorium ani nie wpływał na badania, aby je zdyskredytować.
Nazwał również oskarżenia o tuszowanie sprawy „absurdalnymi”.
Patel powiedział: „Moją misją zawsze było mówienie prawdy, bez względu na konsekwencje i bez względu na to, przeciwko komu się to odbywa.
Autor: AlterCabrio , 3 czerwca 2025
Jeśli była jakaś inżynieria genetyczna i jakieś badania gain of function, to dotyczyły konkretnie białka kolca. Dotyczyły zaplanowania akcji, która miała na celu wprowadzenie powszechnie do organizmów ludzi materiału genetycznego, który będzie zmieniał nasze komórki w fabryki toksyny, właśnie tego białka kolca. I nad tym były jakieś projekty prowadzone i raczej szukano uzasadnienia w obrębie wirusów, koronawirusów, które już gdzieś krążą, żeby uzasadnić konieczność wprowadzenia tego typu technologii w nasze organizmy. Mówią już wprost, mówią naukowcy z Japonii, mówi Peter McCullough ze Stanów Zjednoczonych i jego środowisko, i jeszcze kilku innych niezależnych naukowców, o broni biologicznej. Czyli ja stoję na stanowisku, że Chiny współpracując z pewną grupą wysoko postawionych ludzi w Stanach Zjednoczonych, jeszcze z poprzedniej władzy, opracowali zamach na ludzkie życie i zdrowie poprzez opracowanie sz…ki, która jest preparatem genetycznym, która powoduje dużo różnych powikłań, bardzo różnorodnych, trudnych do rozpoznania. I właściwie to przyspiesza progres różnych chorób przewlekłych populacji.
Dlatego tak trudno jest to obecnie rozpoznać. Bardzo trudno jest to zbadać. Mimo, że jest bardzo wiele doniesień naukowych, które to dokumentują. Więc to był cel. Natomiast Chiny współpracując z pewnymi ważnymi osobistościami, wpływowymi ludźmi, wpływowymi grupami zrobiły taką inscenizację, spektakl na cały świat poprzez wpływ na media, po to, żeby ludzi wystraszyć, żeby ludzie weszli w narrację potężnej, groźnej infekcji, która zabija.
A tak naprawdę to brak dostępu do terapii takich, które skutecznie kontrują objawy grypopodobne, zatrzymanie, zahamowanie właściwie powszechnego dostępu do, w przypadku zapalenia płuc, już nadkażeń, do antybiotyków, czy z opóźnieniem te antybiotyki były podawane. Oczywiście, lockdowny i ogromny strach. Uważam, że jest niedoceniona ta pandemia strachu, celowo skoordynowana.
−∗−
Piotr Witczak ujawnia: Nowy minister zdrowia rozpętuje medyczną rewolucję
Robert F. Kennedy wprowadza zmiany, które wstrząsają światem.
00:00:00 Start
00:00:56 Czy KORONA wyszła z laboratorium?
00:07:11 Czy WOJNA i KORONA są powiązane?
00:12:31 Fragment sponsorowany
00:13:26 O co chodzi z KORUPCJĄ?
00:19:11 Czy wszystko wychodzi przez WYBORY?
00:25:28 Skutki niskich URODZEŃ w Polsce
00:29:53 Czy PREPARAT jest powiązany z AUTYZMEM?
00:39:19 Czy USA przeprowadzi BADANIA?
00:47:11 Dlaczego w PREPARATACH znajdują się metale ciężkie?
00:56:04 Czy dzięki USA coś się zmieni?
01:00:37 Jakie są komentarze po całej SYTUACJI?
01:09:48 Czy jest szansa na POWTÓRKĘ?
01:13:28 Czy Witczak uważa, że WSZYSTKIE preparaty są ZŁE?
01:22:15 Czy w NIEMCZECH jest mniej obowiązkowych preparatów?
https://youtube.com/watch?v=fIE24cnWBw0%3Fsi%3DJZuwBqy-JSKm6Klk
[poniżej to wklejone md]

https://blog.maryannedemasi.com/p/australia-quietly-pivots-on-covid
Nie było konferencji prasowej ani medialnego blitz. Właściwie, nie było żadnego ogłoszenia.
Jednak około 2 maja [na stronie rządowej jest data 2 czerwca] 2025 r. australijski Departament Zdrowia po cichu wycofał zalecenie szczepienia przeciwko COVID-19 zdrowych dzieci i młodzieży poniżej 18. roku życia.
Zmiana została wprowadzona do internetowej aktualizacji Australijskiego Podręcznika Szczepień – nie było nagłówka, oświadczenia ministra ani kampanii medialnej informującej opinię publiczną.
Po raz pierwszy od rozpoczęcia szczepień australijskie władze ds. zdrowia ogłosiły, że dziecko nie potrzebuje szczepionki, chyba że cierpi na choroby współistniejące.
Australia dołącza do rosnącej listy krajów wycofujących się z powszechnego podejścia do szczepień populacji niskiego ryzyka.
W USA urzędnicy ds. zdrowia pod przewodnictwem Sekretarza HHS Roberta F. Kennedy’ego Jr. niedawno wycofali rutynowe zalecenia dotyczące szczepień przeciwko COVID-19 dla zdrowych dzieci i kobiet w ciąży.
CDC pozostawia teraz tę kwestię „ wspólnemu podejmowaniu decyzji ” – milcząco przyznając, że poprzednie uniwersalne podejście mogło być przesadzone.
Tymczasem Dania była o krok przed innymi.
Firma przestała zalecać szczepienie zdrowym dzieciom już w 2022 r., powołując się na dane pokazujące, że ciężki przebieg COVID-19 u dzieci jest niezwykle rzadki, a korzyści płynące z masowych szczepień nie przewyższają szkód.
Zmiana polityki Australii może być spóźniona, ale uderzające jest to, jak cicho została przeprowadzona — i jak wiele jest w niej ukrytych ustępstw.
Przez lata każdy, kto kwestionował potrzebę szczepienia zdrowych dzieci, był odrzucany jako antynaukowy lub niebezpieczny. Teraz te same władze, które szeroko promowały szczepionki, po cichu się z tego wycofują.
A zdarzenia niepożądane, które krytycy podnieśli na początku — zapalenie mięśnia sercowego, zapalenie osierdzia i inne powikłania poszczepienne — nie są już kwestią marginalną. Są uwzględniane w oficjalnych ocenach ryzyka.
Zmiana ta następuje w momencie, gdy ramy prawne i regulacyjne, które umożliwiły szybką akceptację szczepionek mRNA, są poddawane coraz większej kontroli.
W Australii dr Julian Fidge, lekarz rodzinny i były farmaceuta, wytoczył proces, w którym zakwestionował legalność zatwierdzenia szczepionki.
Twierdzi, że szczepionki mRNA firm Pfizer i Moderna powinny zostać sklasyfikowane jako „organizmy genetycznie modyfikowane” zgodnie z ustawą o technologii genetycznej z 2000 r . i w związku z tym przed wprowadzeniem na rynek wymagana jest licencja Urzędu Regulacji Technologii Genetycznej (OGTR).
Sąd jednak oddalił sprawę z przyczyn proceduralnych, orzekając, że dr Fidge nie miał podstaw prawnych do jej kontynuowania.
Sprawa ta zwróciła jednak uwagę na to, czy produkty te nie były kierowane za pośrednictwem niewłaściwej ścieżki regulacyjnej.
To pytanie jest obecnie w centrum petycji obywatelskiej w USA, złożonej do FDA w styczniu 2025 r., w której twierdzono, że agencja „niesłusznie i nielegalnie” zatwierdziła szczepionki mRNA przeciwko COVID-19, traktując je jako konwencjonalne leki biologiczne, a nie terapie genowe.
———————————–
„oni” nie chcą, żebyś to czytał, więc oni umieścili to na pierwszej stronie….
=================================
Autor: AlterCabrio , 2 czerwca 2025
„Teoria wycieku laboratoryjnego przeszła już długą drogę od ledwie marginalnego pomysłu do akceptowalnej alternatywy, ale w 2025 roku spodziewamy się, że przejdzie do fazy końcowej i stanie się poglądem większości.”
−∗−
Tłumaczenie: AlterCabrio – ekspedyt.org
−∗−
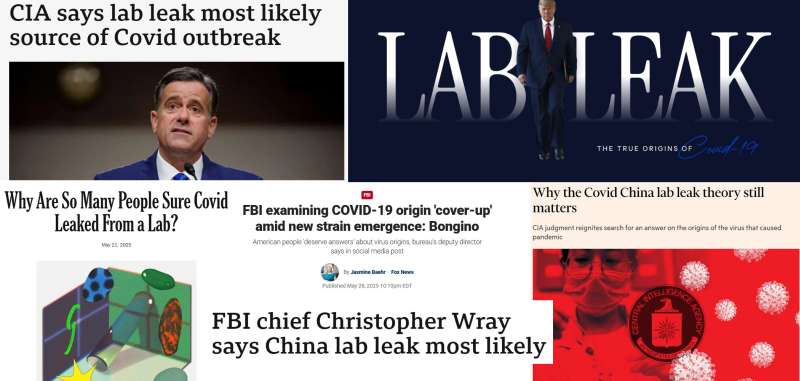
W styczniu, w ramach naszego cyklu „Prognozy na rok 2025”, napisałem, że rok 2025 będzie rokiem ujawnienia wycieku laboratoryjnego i że teoria wycieku laboratoryjnego (LLT) stanie się „prawie oficjalnie prawdziwa” do końca roku:
„Teoria wycieku laboratoryjnego przeszła już długą drogę od ledwie marginalnego pomysłu do akceptowalnej alternatywy, ale w 2025 roku spodziewamy się, że przejdzie do fazy końcowej i stanie się poglądem większości.”
Niecałe dziesięć dni po opublikowaniu tego artykułu CIA oficjalnie potwierdziła pochodzenie przecieku z laboratorium.
W marcu „New York Times” ubolewał nad faktem, że wszyscy „zostaliśmy strasznie wprowadzeni w błąd co do wydarzenia, które zmieniło nasze życie”.
W kwietniu Biały Dom Trumpa dodał do swojej oficjalnej strony internetowej TO:

W zeszłym tygodniu zastępca dyrektora FBI oświadczył w wywiadzie, że FBI prowadzi dochodzenie w sprawie potencjalnego „zatuszowania” pochodzenia covid-19.
W artykule w „New York Times” pojawia się pytanie „Dlaczego tak wiele osób jest pewnych, że covid wyciekł z laboratorium?”, w którym zauważa się, że „szala się przechyla” w sprawie teorii wycieku z laboratorium i argumentuje się – zasadniczo – że teoria LLT może być prawdziwa, ale udawanie, że tak nie było w 2020r., było jedynym sposobem na zapobiegnięcie wzrostowi nastrojów antychińskich.
Wczoraj The Telegraph opublikował tekst:
„Czas na prawdę. Oto dokument o covid, którego nie chcą, żebyś przeczytał – Wszystkie dowody na wyciek z laboratorium w Wuhan, odpowiednio poukładane”
Dokładnie tak, „oni” nie chcą, żebyś to czytał, więc oni umieścili to na pierwszej stronie The Telegraph. To trochę jak zorganizowanie „filmowi, którego nie chcą, żebyś oglądał” efektownej premiery w Londynie.
Cztery dni temu „Miami Herald” poinformował, że 57% Amerykanów uważa obecnie, że LLT jest prawdą. Jest to prawdopodobnie tak samo wiarygodne, jak jakikolwiek inny sondaż opinii publicznej – czyli całkowicie niewiarygodne – ale jest zabawne, ponieważ przewidzieliśmy…
„w 2025 roku spodziewamy się, że [Lab Leak Theory] wykona ostatni krok, stając się poglądem większości. To pogląd większości, nie konsensus. Mówimy o kultywowanym podziale 55-45. Ponieważ argument o naturalnym kontra laboratoryjnym wycieku jest zbyt cenny, aby kiedykolwiek się zakończyć.”
…OK, pomyliłem się o 2%, ale argument jest prawdziwy.
Tak czy inaczej, zrealizujemy teraz ten kupon „A nie mówiłem?”.
Tak naprawdę, niech to będą dwa kupony „a nie mówiłem”. Bo, cóż, pamiętacie, co mówiłem w zeszłym tygodniu o covidzie?
„Widzicie, jak we wszystkim, chodzi o zrównoważenie szali. Nie ma już jednej narracji, zamiast tego machina skupia się na równym rozdzielaniu fałszywej nadziei i bodźca do wściekłości po obu stronach w każdej kwestii”.
Cóż, tak jak The Telegraph promuje badanie, które „udowadnia”, że covid pochodzi z laboratorium, tak South China Morning Post promuje inne badanie, które „udowadnia”, że tak nie jest.
Wybierz swoją stronę. Wybierz swój dowód. I tak w kółko.
_________________
| DR IGNACY NOWOPOLSKI MAY 30 |

Bongino potwierdził, że w badaniu okoliczności pojawienia się wirusa bierze udział wiele oddziałów terenowych FBI, podkreślając prawo społeczeństwa do przejrzystości i odpowiedzialności.
Potwierdzając, że dr Anthony Fauci jest „pod lupą”, oświadczenie to stanowi jedno z najbardziej bezpośrednich potwierdzeń ze strony wysokiego rangą urzędnika FBI dotyczące ciągłego zainteresowania agencji przyczynami pandemii.
Zakres i szczegóły śledztwa pozostają nieujawnione, a FBI nie wydało oficjalnego komunikatu prasowego w tej sprawie.
Rozwój sytuacji wiąże się ze wznowioną dyskusją na temat możliwości laboratoryjnego pochodzenia COVID-19.
W 2023 r. ówczesny dyrektor FBI Christopher Wray wskazał, że agencja oceniła z umiarkowanym przekonaniem, że wirus prawdopodobnie powstał w wyniku incydentu laboratoryjnego w Wuhan w Chinach. Władze Chin konsekwentnie zaprzeczały takim twierdzeniom, określając je jako motywowane politycznie i pozbawione dowodów.
Śledztwo zbiega się również z pojawieniem się nowego wariantu COVID-19, tymczasowo zidentyfikowanego jako NB.1.8.1, wykrytego w kilku stanach USA. Federalni urzędnicy ds. zdrowia nie sklasyfikowali go jeszcze jako wariantu budzącego obawy.
Bongino, mianowany na stanowisko zastępcy dyrektora FBI na początku tego roku przez dyrektora Kasha Patela, znany jest ze swojego bezpośredniego stylu komunikacji i wykorzystuje platformy mediów społecznościowych do dostarczania aktualizacji na temat działań biura. Jego ostatnie oświadczenia podkreślają zaangażowanie FBI w badanie pochodzenia COVID-19 i zapewnienie, że amerykańska opinia publiczna otrzymuje dokładne informacje.
| ROBERT W MALONE MD, MSMAY 29 |
Grok generated MRI image of a vaccine-induced myopericarditis-damaged heart
Polls are beginning to show the impact of the recent roll out of the MAHA commission report and the hearings on COVID genetic product-induced myopericarditis that were held by the Senate Subcommittee on Investigations, chaired by Senator Ron Johnson.

Breaking: Thursday, May 29, 2025 (Rasmussen Reports)
In the wake of recent warnings from the Food and Drug Administration (FDA), about half of Americans think – vaccines against the COVID-19 virus may have caused heart problems for some patients.
The latest Rasmussen Reports national telephone and online survey finds that 51% of American Adults believe it’s likely that the COVID-19 vaccine has caused inflammation in the hearts of many vaccinated Americans, including 29% who think it is Very Likely. Twenty-eight percent (28%) don’t consider it likely that COVID-19 vaccine caused many cases of heart inflammation, and 21% are not sure. (To see survey question wording, click here.)
Earlier this month, the FDA ordered makers of COVID-19 vaccines to expand their warnings about the risk of heart side effects — which doctors call myocarditis (an inflammation of the heart muscle) and pericarditis (inflammation of the membrane surrounding the heart). Sixty-nine percent (69%) of Republicans, 39% of Democrats and 49% of those not affiliated with either major party believe it’s at least somewhat likely that many have suffered heart inflammation caused by COVID-19 vaccine.

May 16th, 2025
A new survey from the Center for Excellence in Polling shows overwhelming and bipartisan support for policies that advance efforts to Make America Healthy Again (MAHA). Results show that voters, regardless of party affiliation, express support for a range of MAHA policies, including transparency and accountability in the food and pharmaceutical industries, healthier options and more transparency in school lunches, and more accountability for federal health care bureaucrats.
The MAHA movement has become a driving force in American politics and at the highest levels of the federal and state governments. Creating a healthier America starts by holding food and drug companies and government bureaucrats accountable by demanding greater transparency, along with reforms to welfare programs that promote health and preserve resources for the truly needy. Voters are clamoring for reform, and the results of this poll show that MAHA policies are both overwhelmingly popular and bipartisan. Policymakers—Democrats and Republicans—in both federal and state governments have a rare opportunity to shape domestic policy in a way that would satisfy the preferences of nearly every American, and they should not let the opportunity go to waste.
As the federal government moves toward promoting a healthier American lifestyle, voters see school lunch programs as the logical place to start. Americans are nearly unanimous in their support for requiring schools to provide fresh fruits and vegetables with every lunch served in the school; indeed, 95 percent of voters say they support this requirement. Meanwhile, in a nod to federalism, 81 percent of voters say that states should be allowed to enact school lunch nutrition standards that are stricter than federal standards, giving states greater control to implement public policy that aligns with the preferences of voters in the state.
Nearly nine in 10 voters (88%) also support greater transparency in school lunch programs. In a rare instance of bipartisan agreement, Republicans (90%) and Democratic voters (89%), along with 86 percent of Independents, are in lockstep on requiring schools to provide parents with a full list of ingredients and nutrition facts for the meals served at the school. Such a move would provide parents with greater information about the foods their children consume at school and provide them meaningful opportunities to hold the schools accountable when they stray from providing healthy meals for children.
Transparency is vital to government accountability, and voters reject the idea of government researchers burying studies that were funded with taxpayer dollars. With near unanimity (95%), voters agree that all government-funded health studies should be made publicly available,even if those studies have negative results. Moreover, voters demand that government agencies and the bureaucrats who work in them be free from any appearance of bias or impropriety arising from financial ties. More than nine in 10 (93%) of voters say that government agencies should be required to disclose financial ties with drug companies and food manufacturers. Meanwhile, nearly as many voters—87 percent—agree that it should be illegal for all government health officials to own stock in companies they regulate.
Let’s go back in time to before the 2024 election. Many Republicans were afraid of voting manipulation. There had been at least two credible assassination attempts against the candidate Donald Trump. Knowing he would face a bruising battle for reelection, Senator Ron Johnson had considered not running for another term, but decided to meet the challenge mainly because of his empathy for those injured by the COVID-19 gene therapy-based products (mRNA and adenovirus vectored).
Lots happened in the closing weeks, including the merger of two campaigns – the Trump/MAGA charging bull coming from the right, and the Kennedy/MAHA insurrection coming from the left. Strange bedfellows who formed what had seemed an improbable alliance forged in the crucible of a spectacular televised assassination attempt.
Truly a historic event, which split a key Democrat party constituency and moved it into the Republican column: MAHA Moms. Much more than merely “suburban housewives”, per Grok, “MAHA Moms” are typically mothers from a broad range of racial, regional, and sociological demographics who advocate for healthier lifestyles, focusing on cleaner food, reduced exposure to toxins, and skepticism toward mainstream medical practices like vaccines. They are often described as „crunchy moms” who prioritize organic, unprocessed foods and natural living, sometimes overlapping with conservative or „medical freedom” ideologies. Many are active on social media, using hashtags like #MAHA or #MAHAMoms to push for food industry reform and share wellness tips. Some MAHA Moms are also momfluencers, promoting „non-toxic” products or alternative health practices, though some positions characterized as “anti-vaccine” and distrustful of medical institutions have drawn criticism from ‘fake news” media for spreading misinformation.


After a stunning election and mandate to govern from the center right, I had the opportunity to speak with the re-elected Senator Johnson as well as many with close contacts to the new leadership of HHS under Secretary Kennedy. In my substack essay endorsing President Trump I had acknowledged that I was not aligned with his position on the genetic vaccine products, but believed that, on balance, he was by far the superior Presidential candidate. But I wanted to understand what would likely transpire regarding these gene therapy-based products that I had called to be withdrawn from the market years before.
| Why I have Endorsed President Trump |
| ROBERT W MALONE MD, MS·AUGUST 28, 2024 |
 |
| The time of choosing is coming soon. |
| Read full story |
Although many within the MAHA and Medical Freedom movements were advocating for immediate legislative action to force the removal of these products from the market, Senator Johnson discussed that he strongly believed that it would be necessary first to build national consensus in support of such action. That attempts to move legislatively without broad voter support would be a fools errand. He spoke about the coming opportunity to ascend to become chairperson of the Senate DHS permanent subcommittee on investigations, at which time he would have the power of the subpoena and could force disclosure of previously redacted or withheld information from the HHS bureaucracy concerning the hazards associated with these products. The Senator’s proposed strategy revolved around what he anticipated would be staged disclosure of key government documents and correspondences that would prove to (and move) US Citizens to support legislative reversal of the laws and policies that gave rise to the COVIDcrisis lies and travesties, and what he refers to as the COVID cartel.
Last week’s hearings by the Senate DHS permanent subcommittee on investigations concerning “The Corruption of Science and Federal Health Agencies: How Health Officials Downplayed and Hid Myocarditis and Other Adverse Events Associated with the COVID-19 Vaccines” were stunning. The strongest indicator of impact that I witnessed while sitting in the audience was the three lobbyists sitting in front of me, whom I am quite sure had no idea who I was. They started out sniggering at Senator Johnson’s opening statement, but as the meeting progressed, they became more and more agitated and distraught. I overheard the senior member calling some colleague outside the conference room, and he was clearly quite upset by the testimony. This is winning, and the Senator clearly understands the politics of all of this, as demonstrated by the recent Rasmussen Reports polling that was just disclosed today.
As to my HHS contacts, what I had been told was that the team would deploy a strategy closely paralleling that of Senator Johnson. Staged deployment of large blocks of well-vetted and substantiated new information concerning the key topics associated with the MAHA agenda, with the intent of overwhelming the ability of “fake news” media to spin and distract from the underlying inconvenient truths. You can think of this as a “Twitter Files” strategy. The intent being to break through the firewall of propaganda and censorship that will be arrayed against the assembled disruptive team and new ideas. Hoping that truth and data will have sufficient power to convince the general citizenry. Hence the massive truth bomb of the MAHA Commission report. Which is the lead in to the second poll cited above- documenting that “American Voters Strongly Support MAHA Policies, Backing Crosses Party Lines.” This is what winning looks like in the land of the blind, where the one-eyed man is king. Many in the MAHA, sponsored and spontaneous, are quite willing and able to build outrage, anger, clicks, likes and follows by shouting that things are not perfect, and Bobby et al are not moving fast enough. But from where I sit on my little homestead in the foothills below the Shenandoah National Park, all of this looks like winning at warp speed.
Bobby is staying true to his ideals, and to the ideals of the MAHA movement that has caught fire with key cross-partisan segments of the American electorate. I think we are on the verge of a major political realignment. Populist movements are always challenged by how to translate their ideals into effective political action and long-term change. Frankly, I have been skeptical that this strange bedfellow alliance of MAHA and MAGA could translate all of the layers of hope and passion into sustainable policy. But with leaders like Secretary Kennedy, Senator Johnson, and President Trump, it is looking a lot like this dream just might come true, at least in the near term.
On the horizon, the multifaceted threat to fundamental truth and reality known as Artificial Intelligence will sweep across all of this and profoundly restructure society, business, and government. Some see that impending period of accelerating change as a threat. I see it as an opportunity. I love disruptive change. Kennedy, Trump, Johnson, Gabbard, and so many others are agents of change, and from the resulting disruption of industries and existing networks of power and control will emerge new opportunities for those with the skills and agility to recognize the opportunities.
Don’t let the nattering nabobs of negativity distract you. This is what winning looks like, and it is glorious. Focus instead on what you can do to adapt to this change, to innovate, and together help create a decentralized “new world order”.
Disruption is king. Long live the disruption.
Thanks for reading Malone News! This post is public so feel free to share it.
Grzegorz Płaczek @placzekgrzegorz x.com/placzekgrzegorz
DRUZGOCĄCE!
Ależ to jest układ zamknięty. Informuję opinię publiczną, iż wreszcie udało mi się dotrzeć do liczb [interpelacja poselska o sygn. PLPR.050.21.2025.PSZ].
Otóż… Polska w ostatnich latach wydawała z budżetu Ministerstwa Zdrowia na zakup szczepionek średnio 135 MILIONÓW ZŁOTYCH ROCZNIE, co daje łącznie (w ciągu ostatnich 25 lat) kwotę 3,3 MILIARDA ZŁOTYCH !!!
I to o to dokładnie idzie ta gra.
To o te pieniądze walczy loby farmaceutyczne i to dlatego na Komisji Zdrowia można spotkać lobbystów Big Pharmy – nazywanych „niezależnymi ekspertami” lub „doradcami”, a Ministerstwo Zdrowia od lat powołuje na stanowisko szefa GIS’u osoby powiązane z branżą farmaceutyczną.
Między bajki można włożyć przekaz kolejnych rządów, że… szczepionki są darmowe.
Nie, nie są!
A przecież do tych miliardów należy doliczyć koszty dystrybucji, utylizacji, transportu, przechowywania, podawania szczepionek, etc. – za co również co roku płacą polscy podatnicy.
Polska ma jeden z najbardziej rozbudowanych programów obowiązkowych szczepień dzieci na świecie!
NA ŚWIECIE!
Czas powiedzieć to głośno – polski budżet państwa jest drenowany przez branżę farmaceutyczną i każdy z kolejnych Ministrów Zdrowia od dekad na to pozwala.
Patologiczny system ma się dobrze i jeśli ktokolwiek myśli, że to wszystko nie ma najmniejszego sensu – podpowiem, że wręcz przeciwnie. Miliardy płyną strumieniami.

Amerykańskie Centrum ds. Chorób i Prewencji (CDC) przestało promować szczepionki na Covid-19 wśród zdrowych dzieci i kobiet ciężarnych.
Taką decyzję podjął sekretarz ds. zdrowia, Robert F. Kennedy. – Dzisiaj szczepionka na Covid dla zdrowych dzieci i zdrowych kobiet w ciąży została usunięta z harmonogramu rekomendowanego przez CDC – poinformował na X. [A wśród chorych chyba tym bardziej?md]
– To element zdrowego rozsądku i rzetelnej nauki. Jesteśmy teraz o jeden krok bliżej do realizacji tego, co obiecał prezydent Stanów Zjednoczonych: uczynienia Ameryki na powrót zdrową [MAHA] – dodał.
Kennedy wystąpił też na krótkim nagraniu razem z rządowymi ekspertami, którzy krytykowali administrację Joe Bidena za promowanie przyjmowanie tzw. dawek przypominających szczepionki na Covid wśród zdrowych dzieci. Ich zdaniem nie uzasadniały tego dosłownie żadne badania kliniczne.
Kilka dni wcześniej rządowa Agencja Żywności i Leków nakazał Pfizerowi oraz Modernie rozszerzenie ostrzeżeń przed przyjmowaniem szczepionki przez młodych mężczyzn w wieku 16 – 25 lat. Chodziło o związek między szczepieniami a chorobami serca.
Źródło: lifesitenews.com Pach
Marek Wójcik https://www.world-scam.com/archive/48820/966-wielki-reset-systemu/
Polityka Donalda Trumpa związana z plandemią koncentruje się na wykazaniu, że to Chiny – jako czarny Piotruś – narzuciły WHO i światu zmyśloną chorobę, natomiast USA – jako ten dobry kraj – nic z tym nie miały wspólnego.
Widać to wyraźnie we wtorkowym przemówieniu R. F. Kennedy Jr, dotyczącym podpisanego traktatu zamordystycznego WHO. Przemówienie moim zdaniem bardzo dobrze przedstawia mafijny charakter organizacji niszczącej zdrowie (WHO).
Podczas gdy Stany Zjednoczone zapewniały lwią część finansowania organizacji w przeszłości, inne kraje, takie jak Chiny, nadmiernie wpływały na pracę organizacji w sposób, który służył ich własnym interesom, a niekoniecznie interesom globalnej opinii publicznej. Stało się to jasne podczas pandemii COVID, kiedy WHO, pod naciskiem Chin, stłumiła raporty dotyczące krytycznych punktów przenoszenia się wirusa z człowieka na człowieka, a następnie współpracowała z Chinami w celu rozpowszechnienia fikcji, że COVID pochodzi od nietoperzy lub pangolinów, a nie od sponsorowanych przez chiński rząd badań w banku biologicznym w Wuhan.
Wybrany urywek z mowy amerykańskiego Ministra Zdrowia R.F.K. Jr, przedstawiony w opublikowanym w czwartek artykule na Report24.news: Restart systemu! Robert F. Kennedy Jr przemawia do ministrów zdrowia na całym świecie.

Nie zamierzam bronić chińskiego rządu, również odpowiedzialnego za kowidowe zbrodnie, zapewne także sponsorował prace w laboratorium Wuhan, jednak zarówno sprawcą, jak i głównym sponsorem były USA reprezentowane wtedy przez szefa CDC, czyli bosa mafii sanitarnej, Antoniego Fauciego.
Sama hipoteza autentycznych laboratoriów jest próbą zagmatwania sprawy plandemicznej propagowaną przez zachodnie media. Nawet jeśli stworzono jakieś mikroby w laboratorium, to nie ma żadnych naukowo uzasadnionych powiązań z jakąś chorobą. Dla celów plandemii wybrano garść znanych medycynie chorób układu oddechowego i wrzucono je do szeroko propagowanego worka z nazwą kowid.
Apel Roberta Kennedy’ego juniora do Ministrów Zdrowia jakkolwiek niezbędny, padnie na grunt uzależnionych od narkotyku władzy skorumpowanych polityków na świecie. Możemy zgadywań, jakie będą jego skutki. Najbardziej podatny na ten apel europejski kraj Słowacja z pewnością poprze tę ideę, może także wystąpi z WHO. Jak na razie Słowacja nie podpisała poddańczego traktatu WHO.

Także w czwartek i również na Report24.news ukazał się artykuł: Gabbard ujawnia tuszowanie pandemii przez Fauciego i Bidena. Źródło.
Pięć lat po rozpoczęciu pandemii, pierwotna historia, że wirus pochodzi z targu zwierząt w Wuhan, już dawno się rozpadła. Zamiast tego istnieje coraz więcej dowodów na to, że prawdziwym źródłem jest wyciek laboratoryjny w WIV [to w Wuhan md], gdzie przeprowadzono badania nad koronawirusami nietoperzy przy wsparciu finansowym USA. Megyn Kelly podkreśliła, że badania te, wspierane przez sieć Fauci, stanowią najbardziej wiarygodne wyjaśnienie katastrofy. Opinia publiczna była przez lata wprowadzana w błąd za pomocą słabej teorii rynkowej, podczas gdy prawda o roli Fauciego i jego zwolenników pozostawała niejasna.
Także tutaj wyraźnie widać, jak zastępuje się jedną fałszywą teorię inną także nieprawdziwą. W obu wersjach zakłada się, że przyczyną pandemii był wirus. Pandemia z roku 2020 nie miała żadnych podstaw medycznych, była wielką zmową i opartą na fałszowaniu faktów próbą generalną do przejęcia władzy nad światem przez grupę bezwzględnych psychopatów.
Ta druga wersja, laboratoryjna, służy ochronie prezydenta Trumpa, który jeszcze niedawno przechwalał się, że za jego kadencji otrzymaliśmy eliksir szczęścia i w ten sposób uratował on całą ludzkość przed wielką zarazą.

Nie chcę bronić Fauciego. On odegrał bardzo ważną rolę w tworzeniu mitu pandemicznego. Teraz stał się zasłużenie kozłem ofiarnym, żeby chronić tych ważniejszych – świadomie, lub nie – współwinnych. Tak zawsze działała polityka.
Trump nie zdawał sobie w pierwszej kadencji sprawy, że Fauci jako jego dorada do spraw zdrowia wprowadza go w błąd. Trudno byłoby uzasadnić świadomą współpracę Trumpa w tworzeniu fałszywej pandemii, której termin wybrano w marcu 2020 roku między innymi dlatego, żeby skutecznie uniemożliwić Trumpowi ponowną wygraną w wyborach w listopadzie tego właśnie roku.
Autor artykułu Marek Wójcik
Dr. Peter McCullough Sat May 24

The human genome consists of all the DNA within a human cell, including both protein-coding genes and non-coding sequences, and is distributed across 23 pairs of chromosomes. A single copy of the human genome contains about 3 billion base pairs of DNA and is organized into 23 distinct chromosomes.
Approximately 8% of the human genome is not strictly human DNA, consisting of remnants of ancient viruses and repetitive sequences thought to have a viral origin. While the human genome contains around 22,000 genes, these viral remnants and repetitive sequences are not considered part of those 22,000 genes.
Because the COVID-19 vaccines were rushed to market, no genotoxicity studies were done. In other words, there were no assurances that the code for Pfizer or Moderna would not find its way into the human genome.
Many don’t feel back to normal even four years after taking mRNA shots made by Pfizer or Moderna. Many are asking if the synthetic mRNA products could have permanently altered them.
Reverse transcription, a process used by retroviruses and certain other organisms, converts mRNA into a DNA copy. This copy can then be integrated into the host’s genome, creating a permanent DNA version of the viral genetic information. The enzyme reverse transcriptase catalyzes this process.
LINE-1 retrotransposons utilize a process called target-primed reverse transcription (TPRT) to convert their mRNA back into DNA, which can then be inserted into the genome. This involves the production of L1 mRNA, its translation into proteins (ORF1p and ORF2p), and the formation of a ribonucleoprotein (RNP) complex. The RNP complex interacts with DNA, where a nick is created, providing a starting point for reverse transcription.
Data from Malmö, Sweden, Hennigsdorf, Germany, and Dallas, Texas, are all arriving at the same conclusion — sadly, both Pfizer and Moderna do permanently alter DNA via reverse transcription. Our featured program this week is with Nicolas Hulscher, MPH, from the McCullough Foundation, Dr. Peter McCullough, and Dr. John Catanzaro, who present data on four cases:
1) no SARS-CoV-2, no vaccine (pre-pandemic sample),
2) COVID-19 illness,
3) and 4) COVID-19 vaccinated.
You will be shocked how vaccination years ago impacts gene expression in cells today.
So let’s get real, let’s get loud on America Out Loud Talk News. This is the McCullough Report!
https://inmodia.de/en/about-us
https://pubmed.ncbi.nlm.nih.gov/35723296
The McCullough Report: Sat | Sun 2 PM ET – Internationally recognized Dr. Peter A. McCullough, known for his iconic views on the state of medical truth in America and around the globe, pierces through the thin veil of mainstream media stories that skirt the significant issues and provide no tractable basis for durable insight. Listen on iHeart Radio, our world-class media player, or our free apps on Apple, Android, or Alexa. Each episode goes to major podcast networks early in the week and can be heard on demand anywhere in the world.
 Dr. Peter McCullough Dr. McCullough is an internist, cardiologist, and epidemiologist managing the cardiovascular complications of both the viral infection and the injuries developing after the COVID-19 vaccine in Dallas, TX, USA. Since the outset of the pandemic, Dr. McCullough has been a leader in the medical response to the COVID-19 disaster and has published “Pathophysiological Basis and Rationale for Early Outpatient Treatment of SARS-CoV-2 (COVID-19) Infection,” the first synthesis of sequenced multidrug treatment of ambulatory patients infected with SARS-CoV-2 in the American Journal of Medicine and subsequently updated in Reviews in Cardiovascular Medicine. He has dozens of peer-reviewed publications on the infection and has extensively commented on the medical response to the COVID-19 crisis in TheHill, America Out Loud, NewsMax, One America News, Victory Channel, NTD, and FOX NEWS Channel. Dr. McCullough has testified on pandemic response multiple times in the US Senate, Texas Senate Committee on Health and Human Services, Arizona Senate, Colorado General Assembly, New Hampshire Senate, Pennsylvania Senate, and South Carolina Senate. On December 7, 2022, Dr. McCullough co-moderated a Senate Panel and concluded that all COVID-19 vaccines should be removed from the market for excess mortality. Dr. McCullough has reviewed thousands of reports, participated in scientific congresses, group discussions, and press releases, and has been considered among the world’s top experts on COVID-19.
Dr. Peter McCullough Dr. McCullough is an internist, cardiologist, and epidemiologist managing the cardiovascular complications of both the viral infection and the injuries developing after the COVID-19 vaccine in Dallas, TX, USA. Since the outset of the pandemic, Dr. McCullough has been a leader in the medical response to the COVID-19 disaster and has published “Pathophysiological Basis and Rationale for Early Outpatient Treatment of SARS-CoV-2 (COVID-19) Infection,” the first synthesis of sequenced multidrug treatment of ambulatory patients infected with SARS-CoV-2 in the American Journal of Medicine and subsequently updated in Reviews in Cardiovascular Medicine. He has dozens of peer-reviewed publications on the infection and has extensively commented on the medical response to the COVID-19 crisis in TheHill, America Out Loud, NewsMax, One America News, Victory Channel, NTD, and FOX NEWS Channel. Dr. McCullough has testified on pandemic response multiple times in the US Senate, Texas Senate Committee on Health and Human Services, Arizona Senate, Colorado General Assembly, New Hampshire Senate, Pennsylvania Senate, and South Carolina Senate. On December 7, 2022, Dr. McCullough co-moderated a Senate Panel and concluded that all COVID-19 vaccines should be removed from the market for excess mortality. Dr. McCullough has reviewed thousands of reports, participated in scientific congresses, group discussions, and press releases, and has been considered among the world’s top experts on COVID-19.[usunąłem z oryg. zachodnie , boć i te „wschodnie” te same zbrodnie popełniały. MD]
| DR IGNACY NOWOPOLSKI MAY 23 |
Od zapobiegania do tuszowania: maskowana odpowiedzialność systemów opieki zdrowotnej
Gdy wiosną 2021 r. ruszyły ogólnoświatowe kampanie szczepień przeciwko COVID-19, politycy, media i władze jednomyślnie mówili o „braku alternatywy” dla rozwiązania pandemii. Technologia mRNA była chwalona, a krytycy byli oczerniani.
Teraz stało się jasne, że odpowiedzialne władze bardzo wcześnie wiedziały o poważnych skutkach ubocznych i zgonach – i nic nie zrobiły.
Nowe doniesienia z Kanady i USA potwierdzają to, co podejrzewano od dawna:
Eksplozywny artykuł w serwisie Substack autorstwa Scoopsa McGoo opiera się na ponad 2000 stronach wewnętrznych dokumentów Agencji Zdrowia Publicznego Kanady (PHAC), które zostały upublicznione na podstawie wniosku o udostępnienie informacji publicznej. Wewnętrzne wiadomości e-mail pokazują, że odnotowano ponad 300 zgonów po szczepieniu – jednak PHAC zdecydował:
„300 zgonów to za dużo, żeby je badać”.
Władze Kanady najwyraźniej nie miały ani zamiaru, ani możliwości zbadania każdego przypadku zgonu pod kątem możliwych przyczyn związanych ze szczepieniem. W tym samym czasie badania krytyczne były ignorowane lub odrzucane jako „niewiarygodne”. Szczepienia kontynuowano bez przeszkód.
Tymczasowy raport opublikowany przez senatora USA Rona Johnsona 21 maja 2025 r . ujawnia, że wysocy rangą federalni urzędnicy ds. zdrowia już w lutym 2021 r. wiedzieli o wystąpieniu dużej liczby przypadków zapalenia mięśnia sercowego wśród młodych ludzi, którzy otrzymali szczepionkę Pfizer. Niemniej jednak:
Administracja Bidena czekała do końca czerwca 2021 r., zanim zmieniła etykiety szczepionek i oficjalnie ostrzegła opinię publiczną.
Do tego czasu zaszczepiono miliony młodych Amerykanów – pomimo wewnętrznych ostrzeżeń CDC i FDA. Według raportu Johnsona urzędnicy państwowi celowo wybrali „komunikację niealarmistyczną”, co w praktyce oznaczało brak przejrzystości, brak publicznej debaty i brak ostrzeżenia.
Krytycy, którzy wcześnie wskazali ryzyko – tacy jak dr Tracy Beth Hoeg – zostali ocenzurowani w mediach społecznościowych lub określeni jako osoby rozpowszechniające dezinformację.
To, co udokumentowano w Kanadzie i USA, nie jest odosobnionym przypadkiem . Liczne przesłanki wskazują na to, że wszystkie kraje zachodnie posiadające zorganizowane systemy opieki zdrowotnej ukrywały podobne informacje . Przegląd:
Dowody mówią same za siebie. Poza granicami państwowymi państwa zachodnie prowadziły politykę całkowitego utożsamiania się z kampanią szczepień. Ryzyko zostało zbagatelizowane, a szkody przemilczane – dosłownie. Wielu obywateli zostało de facto zmuszonych do szczepień ze względu na presję społeczną, zawodową lub moralną. A gdy zaczęły się pojawiać pierwsze zgony, ludzie odwracali wzrok.
Nie są to „godne ubolewania, odosobnione przypadki”. To rozpad systemu opieki zdrowotnej , któremu towarzyszy nieodpowiedzialność polityczna i współudział mediów.
===============================================================
![]() Scoops’ Gazette
Scoops’ Gazette
The tragic died suddenly phenomenon is real, and Canada’s Public Health Agency has been tracking it. The shock of an unexpected death is particularly painful and confusing for the victim’s family and friends…
a month ago · 119 likes · 32 comments · Scoops McGoo
https://nebenwirkungen.bund.de
https://yellowcard.mhra.gov.uk
Thanks for reading Dr’s Substack! Subscribe for free to receive new posts and support my work.
Dr’s Substack is free today. But if you enjoyed this post, you can tell Dr’s Substack that their writing is valuable by pledging a future subscription. You won’t be charged unless they enable payments.
Ministerstwo śmierci i choroby
Anthony Ivanowitz 22.05.2025r. pospoliteruszenie.org/ministerstwo/smierci
Jedną z głównych przyczyn ogromnej ilości chorób i zgonów na choroby tak zwane cywilizacyjne, jest…. polityka zdrowotna poszczególnych państw narzucona im przez światowe lobby farmaceutyczne.
Polityka ta polega na uczynieniu z medycyny ogromnego biznesu obliczonego na maksymalizację zysku, podobnie jak to obowiązuje w każdej innej działalności gospodarczej!
Polityka ta prowadzi w prostej linii do ludobójstwa, czego apogeum stanowiła tak zwana pandemia kowida, czyli wywołana sztucznie panika w skali całego świata, pod pretekstem „nowej” choroby którą okazała się znana od stuleci…grypa.
Ogólnoświatowa panika posłużyła mafii farmaceutycznej do „wyszczepienia” miliardów ludzi jakimś specyfikiem, którego produkcja zapewniła jej niebotyczne zyski, a przy okazji poprzez zatrucie miliardów ludzi na całym świecie utworzyła ogromną ilość schorowanych ludzi którzy staną się dozgonnymi klientami koncernów farmaceutycznych.
Podam kilka przykładów pokazujących jak polityka zdrowotna państwa oparta na zasadach biznesowych, prowadzi do ludobójstwa.
Chęć maksymalizacji zysku przez personel medyczny całkowicie niszczy w nim ludzkie odruchy, czyniąc z nich żarłoczne, krwiożercze hieny!
Polska medycyna jest „liderem” w amputacji tak zwanych stóp cukrzycowych.
Według raportu OECD (Organizacja Współpracy Gospodarczej i Rozwoju) z 2019 r. Polska była jednym z krajów o najwyższym wskaźniku amputacji kończyn dolnych wśród 30 analizowanych państw, z wynikiem 7,5 amputacji na 10 tys. chorych na cukrzycę. Niestety, w 2023 r. wskaźnik ten wzrósł do 8,6 amputacji na 10 tys. chorych. Dla porównania, w Holandii wynosił on 5,5, w Szwecji 3,4, a we Włoszech 2,5.
Polska znajduje się więc w czołówce krajów z wysoką liczbą amputacji z powodu zespołu stopy cukrzycowej. ( https://www.medonet.pl/biznes-system-i-zdrowie/trendy-w-ochronie-zdrowia,polska-w-czolowce-amputacji-stop-cukrzycowych–nowy-pilotaz-ma-to-zmienic,artykul,40380996.html )
Jak wyjaśnić ten tragiczny rekord?
W prosty biznesowy sposób: za obcięcie stopy NFZ płaci 5 tysięcy złotych, zaś za jej leczenie…4 tysiące. ( https://www.bankier.pl/wiadomosc/NFZ-wiecej-placi-za-amputacje-stopy-cukrzycowej-niz-za-leczenie-1878915.html )
Opisany proceder amputacji stóp cukrzycowych, (bo za to dobrze płacą) jest tym bardziej skandaliczny, że cukrzyca (zwłaszcza typu II) jest łatwo uleczalna bez żadnych leków, poprzez zmianę diety na nisko węglowodanową.
Tylko który lekarz powie o tym pacjentowi, skoro w wyniku takiej porady straci klienta, któremu może uciąć stopę za 5 tysięcy złotych?
W innych „działach” medycyny horror jest jeszcze większy!!
W kardiologii jest jeszcze gorzej! W latach sześćdziesiątych ubiegłego wieku podstawowym lekiem nasercowym (stosowanym w zawałach serca) była strofantyna.
Podana dożylnie podczas zawału serca, w ciągu kilkunastu minut likwidowała zawał i jego skutki. Była na wyposażeniu lekarzy pogotowia, w przychodniach rejonowych i wszystkich szpitalach. Lek ten miał jedną wadę: był tak tani, że nie sposób było na jego produkcji i stosowaniu cokolwiek zarobić. Więc jego produkcja została w Europie zakazana, na rzecz „nowoczesnego” leczenia zawałów, poprzez procedury wszczepiania stentów, z których każdy kosztuje ok 10 tysięcy złotych. 40% pacjentów tak leczonych nie dożywa 10 lat, ale jest to wystarczająco długi okres aby każdego „wydoić” z kasy!
Onkologia to już ludobójstwo w pełnej krasie. Narzucone przez farmację procedury leczenia chorób nowotworowych ( operacja, chemioterapia, radioterapia) prowadzą prawie do 100 % śmiertelności. Tylko 3 % pacjentów dożywa 5 lat, pozostali giną zabici „nowoczesną procedurą”. Jest ona najbardziej dochodowym biznesem w medycynie, przynoszącym szpitalom i lekarzom dochód w granicach ok 300 tysięcy złotych od zabitego nieszczęśnika.
Grozę sytuacji potęguje fakt, że średni okres przeżycia pacjentów z chorobą nowotworową, nie leczonych w żaden sposób wynosi 12,5 roku!
Czy z przedstawionej matni „zdrowotnej” jest wyjście?
Zauważmy, że największe wydatki na świecie na ochronę zdrowia ponoszą Amerykanie, jednocześnie stan zdrowia tej populacji jest jednym z najgorszych na świecie!
W społeczeństwie amerykańskim istnieje jedna grupa społeczna, będąca na tle całego społeczeństwa okazem zdrowia! Tą grupą społeczną są Amisze, którzy odrzucają medycynę Rokefelerną, co zapewniło im zdrowie na poziomie nieznanym pozostałym Amerykanom. ŻADNE dziecko Amiszów nie ma raka, cukrzycy ani autyzmu. Wśród Amiszów wskaźnik przeżywalności COVID-19 był 90 razy wyższy niż wśród reszty Ameryki. (więcej na temat zdrowia Amiszów tutaj: https://www.dakowski.pl/zadne-dziecko-amiszow-nie-ma-raka-cukrzycy-ani-autyzmu/ )
Jak wyjść z przedstawionej matni?
Drogę wyjścia pokazali Amisze! Odrzucić medycynę opartą na biznesie i powrócić do „korzeni”, czyli medycyny naturalnej naszych babć.
Kto tego nie zrozumie, zginie „leczony” nowocześnie, wcześniej ograbiony z oszczędności!
Anthony Ivanowitz
22.05.2025r.
================================
Muszą odpowiedzieć na pytanie: ile przypadków nigdy nie zostało zbadanych – lub celowo nigdy nie zostało potwierdzonych?
==================================
| DR IGNACY NOWOPOLSKI MAY 22 |
20 maja 2025 r. w czasopiśmie International Journal of Forensic Sciences opublikowano wstrząsający przypadek , który prawdopodobnie będzie miał daleko idące konsekwencje prawne i polityczne: włoskie władze ds. zdrowia uznały odpowiedzialność “szczepionki” covida za śmierć “zaszczepionego”.
Jest to rzadki, ale wyraźnie udokumentowany precedens – i przełomowy moment w kwestii odpowiedzialności za szczepienia.
Według raportu, zgodnie z dokumentacją medyczną, mężczyzna przed szczepieniem znajdował się w „doskonałej kondycji fizycznej”. Dwa tygodnie po podaniu pierwszej dawki szczepionki ChAdOx1 nCoV-19 (AstraZeneca)wystąpiły ciężkie objawy: wysypka, gorączka, duszność. W szpitalu jego stan gwałtownie się pogorszył. Po 15 dniach pobytu w szpitalu i łącznie 43 dniach od szczepienia pacjent zmarł.
Thanks for reading Dr’s Substack! Subscribe for free to receive new posts and support my work.
Sekcja zwłok ujawniła niepokojące wyniki: masywna zakrzepica , szczególnie w mikrokrążeniu tętniczym , doprowadziła do niewydolności wielonarządowej w wyniku koagulopatii spowodowanej zużyciem krwi . Obecna na badaniu komisja lekarska stwierdziła, że zgon był bezpośrednim skutkiem szczepienia .
Przypadek ten nie jest odosobniony. Podobne powikłania – w szczególności dobrze znany zespół VITT (immunologiczna małopłytkowość zakrzepowa wywołana szczepieniami) – odnotowano już w 2021 r. w kilku krajach, w tym w Niemczech, Wielkiej Brytanii i Tajlandii. Rzadko jednak tak wyraźny związek przyczynowo-skutkowy został oficjalnie potwierdzony, nie mówiąc już o jego zrekompensowaniu.
W tym przypadku jednak presja była ewidentnie zbyt duża: włoski rząd zapłacił , a dokumentację naukową upubliczniono – choć w podobnych przypadkach zazwyczaj preferowano milczenie i deeskalację medialną.
Pozostaje pytanie systemowe: jeśli państwo wyraźnie uznaje i rekompensuje zgony związane ze szczepieniami – kto ponosi wówczas odpowiedzialność polityczną i medyczną? Gdzie jest publiczna debata na temat oceny ryzyka, edukacji i kontroli?
Zamiast tego czytamy dalej: „Tragiczny, odosobniony przypadek”. Prawie żadne główne medium nie wspomina jednocześnie o tym, że szczepionka AstraZeneca została ostatecznie wycofana z rynku przez EMA w maju 2024 r .
Sprawa ta dowodzi po raz kolejny: prawdę może ujawnić tylko sekcja zwłok.Fakt, że ta ostatnia forma informacji medycznej została pominięta w wielu krajach podczas pandemii, rzuca złe światło na sposób radzenia sobie z powikłaniami związanymi ze szczepieniami – i na wiarygodność narracji dotyczących zdrowia publicznego.
Przyznanie się agencji rządowej do śmierci w wyniku szczepienia jest punktem zwrotnym – pod względem prawnym, medycznym i społecznym. Pokazuje to, że nawet w przypadku wysoce upolitycznionej kampanii szczepień, nie da się wiecznie ukrywać prawdy. Potrzebni są odważni patolodzy, niezależni eksperci i, przede wszystkim, opinia publiczna, która zwróci na to uwagę.
Bo jeśli śmierć człowieka jest najpierw cicho przyjmowana do wiadomości, a potem powszechnie ignorowana, to pozostaje pytanie: ile przypadków nigdy nie zostało zbadanych – lub celowo nigdy nie zostało potwierdzonych?

By Rhoda Wilsonon expose/debbie-lerman-exposes-the-real-covid-story
[W oryg. tu można klepnąć, by wysłuchać. md]
The covid pandemic response was not a public health response but rather a global operation coordinated by national security agencies and public-private partnerships, following a biodefense and/or counterterrorism playbook.
The response was characterised by widespread panic, lockdowns and vaccination efforts, which were disproportionate to the actual threat posed, and were driven by a global cartel of powerful interests.
Rebekah Barnett interviewed Debbie Lerman about her book, ‘The Deep State Goes Viral: Pandemic Planning and the Covid Coup’ which reveals the underlying networks of control and the shift of power from national governments to global cartels.
Lerman argues that people must stop focusing on short-term political fixes and instead build alternative systems based on local community and human values.
Let’s not lose touch…Your Government and Big Tech are actively trying to censor the information reported by The Exposé to serve their own needs. Subscribe now to make sure you receive the latest uncensored news in your inbox…
Type your email…
What if the pandemic response was run by national security agencies according to a biodefense/counterterrorism playbook, rather than by public health agencies according to public health guidelines?
This is the question at the core of a new book by friend and Brownstone Institute colleague Debbie Lerman.
Debbie’s contention is this: If it had been a regular public health response, covid would not have differed that greatly from any of the viral epidemics or pandemics of the last century.
The public would have been told to remain calm, wash hands frequently, and stay home if sick. Public health agencies would have tracked clusters of severe disease and treated them accordingly. This would have happened at different times, in different locations. Most people would barely have been aware that there was a novel virus circulating among them.
Instead, the response to covid was the exact opposite. The media and public health agencies whipped the population into levels of panic massively disproportionate to the threat actually posed by the virus. Everyone was convinced that the only way to “beat the virus” was to lock down the whole world and wait for a never-before-tested or manufactured vaccine.
Why?
As a former science writer with a knack for deep investigative thread-pulling, Debbie is well-placed to attempt an answer to this question, in her new book, ‘The Deep State Goes Viral: Pandemic Planning and the Covid Coup’.
While readers may have come across Debbie’s articles before on her Substack or on the Brownstone Journal, the book ties everything together in a way that reading disparate articles across time (and platforms) cannot quite.
I had the privilege of working on this book in its final stages and, having read it from start to finish, can attest that this is recommended reading for anyone with an interest in the bigger, “network level” picture. Debbie also deep dives into the weeds when required to demonstrate with forensic detail the degree to which the official covid narrative simply does not add up.
Following is my interview with Debbie Lerman.
RB: Congratulations on finally publishing your book Debbie, and on hitting #1 in Amazon’s Public Policy reads in the first week of the Kindle edition launch!
DL: Thanks Rebekah – your help was invaluable!
RB: What is the main thing you want people to know about the worldwide covid event – and why does it matter?
To quote the ‘COVID Dossier’, which I published with independent researcher Sasha Latypova, covid was not a public health event, although it was presented as such to the world’s population. It was a global operation, coordinated through public-private intelligence and military alliances and invoking laws designed for CBRN (chemical, biological, radiological, nuclear) weapons attacks.
This is so crucial because it shifts the focus from the false narrative of public health to the real story: the underlying global powers whose networks of control were at least partially revealed during the covid operation.
When we think about all the terrible totalitarian actions that were taken by nearly every government around the world during covid, we need to realise that it was not a series of misguided or mistaken public health decisions. It was an intentional, coordinated global project run by a huge public-private partnership network.
Realising this means that we cannot blame any individual (e.g. Fauci) or government or company for what happened. We have to address the much bigger and less easily solvable problem of how power and control are shifting away from national governments and into the hands of global cartels.
Here’s the global cartel that ran covid, presented both on the US and on the global levels:

The implications are so disturbing that most people don’t want to face them: Our national governments are not working on our behalf. They are working for the global cartels that are amassing more power and resources and working on ways to surveil, censor and propagandise us so we do not see or oppose what they are doing.
It’s had to wrap one’s mind around this, but I believe it is essential if we are to move toward any kind of solution: We have to stop focusing on the short-term political “fixes” in each of our countries (all political parties are just different sides of the same global technocratic control coin), opt out of the completely corrupted political systems, defend ourselves against control and surveillance operations (of which covid was one), and build alternative systems on a local level that are based on real community and human values.
RB: Your book focuses mainly on the American experience and legislation, but you have also documented similar legal frameworks in other countries. What does your book tell us about how and why so many countries end up taking the same “lockdown until vaccine” approach?
DL: In the book, I cover the covid military/intelligence operations in the US and I touch on the equivalent systems in the UK, Holland and Germany. After the book manuscript went to the publisher, I worked extensively on the ‘COVID Dossier’, which documents parallel structures in charge of the covid response in many countries around the world.
Read more: The COVID Dossier, Expanded, Debbie Lerman, 25 March 2025
My book and subsequent work on the Dossier show that all countries in the Five Eyes and NATO military and intelligence alliances followed identical lockdown-until-vaccine response protocols, which indicates global coordination of these protocols.
RB: I learned so many nuggets that I’d never heard of before from reading your book. For example, Dr Peter Dazsak – who has been debarred from HHS funding for his alleged role in facilitating gain-of-function research in Wuhan – served as a US representative on the WHO covid origins investigation. Conflict of interest much? I can’t believe he got away with that. What were some things you turned up in your research that really surprised you?
DL: First, I just want to clarify that Dazsak never actually got debarred from anything. In a 16 May 2024, Substack article entitled ‘Peter Daszak Gets DOD and CIA Funding. Why Don’t They Ask About That?’ I went into great detail showing how everything the “US House Committee on Oversight and Accountability” said they were doing to “punish” Daszak for conducting dangerous gain-of-function research was pure theatre.
Most of Daszak’s funding – and funding for all gain-of-function research – comes from military or intelligence agencies, because it’s all about bioweapons and countermeasures, and such research is not subject to any public health oversight or regulations. It’s all part of the operations of the biodefense public-private partnership, as detailed above.
One of the lessons of covid – and hopefully of my book – is that hundreds and thousands of scientists, biowarfare experts, military/intelligence operatives, pharma execs, consultants, academics and medical professionals from around the world populate all of the global biodefense companies and agencies, which means that apparent conflicts of interest are immaterial, because the global-public private partnerships are not subject to any national or Constitutional laws or oversight.
As far as surprises: When I first started my research on covid, I was completely shocked to discover that Deborah Birx, the Coordinator for the US Government’s Covid-19 Response Task Force, wrote a book called ‘Silent Invasion’ that was pretty much outright lies from beginning to end. Several chapters in ‘The Deep State Goes Viral’ document that discovery. They are based on articles first published by Brownstone.
Then I discovered that famous journalists and authors also wrote blatant propaganda about covid. The one I researched most deeply was Michael Lewis, and his book ‘The Premonition’– which, like Birx’s book, is full of obfuscations and falsehoods. I devoted a section of my book to that investigation and other discoveries I made about blatant propaganda in The New York Times and other major publications.
And, of course, I was completely floored when I discovered the Government document that showed that the National Security Council was in charge of the US government’s covid response policy, and when I subsequently found that FEMA and the Department of Homeland Security had replaced the public health agencies as leaders of the response. That’s what really got me going on all the research in the book.
RB: I see the hard copy of your book is being presented in the World History section on Amazon. Why are narratives so important to our understanding of history, and what do you see as the main competing narratives for our understanding of the pandemic era?
Great question! At first I was surprised to see that Brownstone chose to list the book under World History, but then I realised that it does document one of the most significant global events of the 21st century, if not of all time.
I know that sounds bombastic, but the coordination of the vast global covid operation, which affected nearly every human being on Earth, was enabled through digital tools of surveillance, censorship, propaganda and control that were not available to earlier totalitarian leaders or societies.

The competing narrative is the product of the global propaganda and censorship industrial complex which does not want us to focus on its global totalitarian nature and is trying to distract, misdirect and bamboozle us into thinking that covid was all just a bunch of bad public health decisions, and that we can fix it by voting for a different political party or publishing more studies about how masking doesn’t work.
In the book, I summarised it this way: “One of the most ingenious aspects of the global covid operation is that it was so brazen, so extreme, and so inconceivable – that it can actually hide behind its own implausibility.”
RB: Once people learn that the covid response was a military countermeasure, not a public health response, then what? What are you hoping people will do with the information they learn from your book?
DL: To be precise, the word “countermeasure” applies to the covid vaccines and all other treatments used against the “deadly virus.”
The covid response was a globally coordinated coup by the biodefense cartel (as described above) against the populations of the world.
I’m hoping that when people realise this, they will understand that their governments are not acting on their behalf, but rather on behalf of the global corporations and billionaires that partnered with the military and intelligence agencies in nearly every country on earth to deprive all of us of our rights and liberties.
Our governments lied to us. They told us we had to wear masks, lock ourselves up for months and years on end, deprive our children of education and socialisation, and suffer loss of jobs, loss of income, loss of health and loss of life to combat a virus that was known in early 2020 to be dangerous only to very old people with multiple ailments.
Then they bombarded us with propaganda to cover all that up and force everyone to take unregulated, dangerous injections.
If we do not want such totalitarian measures to be unleashed on us again, we need to stop falling for the political, partisan distractions that pit us against each other instead of against our oppressors. I know it’s hard for people to hear this, but covid should be a wake-up call in this sense: the important battle being waged in the world right now is not right vs. left, liberal vs. conservative, socialist vs. capitalist etc. etc. etc. The only real battle is between the global elites and the rest of us.
We need to call our governments out on every lie, every act of censorship or propaganda, and every attempt to digitally surveil and control us, no matter which political party or politician is in charge.
RB: Do you anticipate we will see a repeat of the covid response in our lifetime?
DL: I hope people will not agree to another covid response. But I do anticipate other global events that will further consolidate the wealth, power and control of the global cartels. There might be a “climate crisis” or a “cyber terrorist attack” or a financial crisis. Or all of the above.
What I desperately hope people might take away from my book is that:

RB: What are you working on next?
I’m working mainly on promoting my book and writing for my Substack (see HERE).
Thank you so much Rebekah for your fearless journalistic work and for helping me with mine!
‘The Deep State Goes Viral: Pandemic Planning and the Covid Coup’ by Debbie Lerman is now available in paperback and digital (Amazon links: US, AU, UK ) and on Audible.
Rebekah Barnett is an Australian independent journalist. You can follow Barnett on her Substack page ‘Dystopian Down Under’ HERE, Twitter HERE and Instagram HERE. To support her work, you can make a one-off contribution to Dystopian Down Under’s Ko-fi account HERE.
She is also a volunteer interviewer for ‘Jab Injuries Australia’, a website that collects stories of people who claim to have been injured by covid vaccines.

The Expose Urgently Needs Your Help…

Can you please help power The Expose’s hosest, reliable, powerful and truthful journalism?
Your Government & Big Tech organisations
try to silence & shut down The Expose.
So we need your help to ensure
we can continue to bring you the
facts the mainstream refuse to…
We’re not funded by the Governmenrt
to publish lies and propagandas on their
behalf like the Mainstream Media.
Instead we rely solely on your support. So
please support us in ourt efforts to bring
you honest, relisble, investagative journslism
today. It’s secure, quick and easy…
Please just choose your preferred
method to show your support…



| DR IGNACY NOWOPOLSKI MAY 21 |
Harry Fisher

Panie Prezydencie Biden,
Piszę do Ciebie pewną ręką, ale z ciężkim sercem. Jako technik ratownictwa medycznego z ponad dwudziestoletnim doświadczeniem na pierwszej linii medycyny ratunkowej byłem świadkiem czegoś więcej niż przerażającego. Coś, co przydarzyło się także tobie.
Niedawno zdiagnozowano u ciebie nieuleczalnego raka prostaty z przerzutami do kości, co tragicznie wpisuje się w schemat, który moi koledzy i ja obserwujemy w całym kraju: szybko postępujące nowotwory, których nie da się przewidzieć. Obecnie ten koszmar nazywamy „turborakiem”, ponieważ nie ma ustalonego medycznego terminu opisującego to, co widzimy.
Dla nas, pracowników służb ratunkowych, schemat jest jasny: U dotychczas zdrowych osób w ciągu kilku tygodni od wystąpienia pierwszych objawów rozwijają się agresywne, śmiertelne nowotwory. Jaka jest wspólny mianownik? Szczepionka mRNA. Przebieg Twojej choroby również idealnie wpisuje się w ten obraz.
Narzucili te eksperymentalne produkty milionom Amerykanów. Stanęli na mównicy i powiedzieli niezaszczepionym, że ich [katów? md] „cierpliwość się skończyła”. Podzielili nasz kraj i za pomocą wygórowanych środków nacisku odebrali ludziom prawo do samostanowienia o swoim ciele. Napuściłeś agencje federalne na firmy i zagroziłeś im ruiną gospodarczą, jeśli nie będą egzekwować twoich rozkazów.
A teraz czeka cię ten sam los, co niezliczone rzesze Amerykanów, którzy zaufali zapewnieniom twojego rządu.
Warstwa po warstwie przenoszą rodziców, dzieci, bliskich – wszystkich z tą samą wstrząsającą historią. Zdrowi przed szczepieniem, teraz wyniszczeni przez agresywne nowotwory, których postęp nawet onkolodzy prywatnie opisują jako „bezprecedensowy”.
Tego typu nowotwory nie rozwijają się naturalnie. Przebiegają od zera do śmierci w bardzo krótkim czasie – w ramach czasowych, które wywracają do góry nogami całą naszą wiedzę na temat raka.
Firmy farmaceutyczne, które chronią cię dzięki immunitetowi prawnemu, osiągają rekordowe zyski, podczas gdy dotknięte chorobą rodziny zmagają się z finansowymi i egzystencjalnymi konsekwencjami śmiertelnej diagnozy. Organy regulacyjne, którym przewodniczysz, stały się drzwiami obrotowymi dla przedstawicieli branży, którzy po „świadomej” bezczynności wracają do swoich biur.
Na oddziałach ratunkowych, w karetkach pogotowia i na oddziałach onkologicznych w całej Ameryce pracownicy służby zdrowia widzą to samo, co ja. Oni dochodzą do tych samych wniosków. Wielu milczy ze strachu – ale ta cisza zaczyna się przełamywać. Tama kłamstw pęka – a ty stoisz u stóp fali przypływu, którą pomogłeś wywołać.
Twoja diagnoza jest momentem rozliczenia. Czy wykorzystasz pozostały czas, aby uznać możliwość, że przepisywane przez ciebie produkty powodują niezliczone szkody? Czy nadal będziecie chronić te instytucje i korporacje, które zniszczyły społeczeństwo?
Nie spodziewam się, że kiedykolwiek przeczytasz ten list. Siły instytucjonalne wokół ciebie mają wszelkie interesy we wspieraniu narracji, że te produkty są „bezpieczne i skuteczne”. A jednak to piszę – bo prawdę trzeba mówić, nawet jeśli jest nikła nadzieja, że zostanie usłyszana.
Mam nadzieję, że diagnoza da ci głębszy wgląd i odwagę, abyś w końcu zbadał, co dzieje się z tymi Amerykanami, którzy zaufali poradom medycznym swojego rządu.
Z głębokim zaniepokojeniem,
Harry Fisher,
technik ratownictwa medycznego
do wiadomości: Sekretarz Zdrowia i Opieki Społecznej Robert F. Kennedy Jr.
Niech cię Bóg błogosławi.
Wśród Amiszów wskaźnik przeżywalności COVID-19 był 90 razy wyższy niż wśród reszty Ameryki.
888 Umfassende Studie: KEIN Amish-Kind hat Krebs, Diabetes oder Autismus. WARUM ?
— Daniel Gugger 888 (@daniel_gugger) May 17, 2025
SD Wells, 7.7.2023
„Die derzeitige Zahl der Amishe in Amerika nähert sich rasch der 400.000-Marke, wobei die größte Konzentration mit 90.000 Menschen in Pennsylvania und 82.000 in Ohio zu finden… pic.twitter.com/Yn8JNpDrvM
Kompleksowe badanie: ŻADNE dziecko Amiszów nie ma raka, cukrzycy ani autyzmu.
DLACZEGO ?
SD Wells, 7 lipca 2023 r.
„Obecna liczba Amiszów w Ameryce szybko zbliża się do 400 000, przy czym największe skupiska, liczące 90 000 osób, znajdują się w Pensylwanii, a 82 000 w Ohio. Amisze żyją już w 32 stanach USA i mają średnio 7 dzieci na rodzinę, co oznacza, że populacja szybko rośnie.
W zupełnie nowym, kompleksowym badaniu (stan na czerwiec 2023 r.), przedstawionym Senatowi Stanu Pensylwania przez Steve’a Kirscha, obliczono, że typowe choroby przewlekłe praktycznie nie występują lub są bardzo rzadko spotykane u dzieci amiszów, które są w 100% niezaszczepione.
Do przewlekłych schorzeń, nazywanych również chorobami i zaburzeniami, którym można zapobiegać, a które dotyczą niemal wszystkich zaszczepionych dzieci w populacji USA, zalicza się choroby autoimmunologiczne, choroby serca, cukrzycę, astmę, ADHD, zapalenie stawów, raka i oczywiście autyzm (ASD i zespół Aspergera).
Eksperci zasiadający w panelu zeznawali na temat zdrowia dzieci amiszów w porównaniu do zaszczepionych dzieci amerykańskich. Być może zniechęcanie ludzi do szczepień jest dobrym pomysłem dla wszystkich fanatycznych zwolenników szczepień, którzy uważają, że każdy zwolennik naturalnego zdrowia jest „teoretykiem spiskowym”, gdy mówi o brudnych szczepionkach, skutkach ubocznych poszczepiennych i zgonach poszczepiennych.
W swoich zeznaniach aktywiści na rzecz zdrowia wyjaśnili, dlaczego raporty na temat zdrowia dzieci amiszów w ogóle nigdy nie zostały opublikowane:
„Po dziesięcioleciach badań nad Amiszami nie powstał żaden raport, ponieważ jego opublikowanie byłoby druzgocące. Pokazałoby to, że CDC (Centra Kontroli i Zapobiegania Chorobom) szkodziło społeczeństwu przez dziesięciolecia, nic nie mówiąc i ukrywając wszystkie dane. Dr Peter McCullough, czołowy amerykański kardiolog, autor wielu recenzowanych i opublikowanych prac, zeznawał przed Senatem Stanów Zjednoczonych i legislaturami w całych Stanach Zjednoczonych na temat zagrożeń związanych ze szczepionkami, w tym szczepieniami przeciwko mutacji genu COVID-19.
A skoro mowa o pandemii: Amisze NIE izolowali się, NIE nosili masek i z pewnością NIE „zaszczepili się” przeciwko grypie w laboratorium w Wuhan. Zignorowali wszystkie recepty, łącznie ze śmiertelnymi zastrzykami przeciwzakrzepowymi. I zgadnij, co się stało?
Wśród Amiszów wskaźnik przeżywalności COVID-19 był 90 razy wyższy niż wśród reszty Ameryki.
Oprócz zwolenników naturopatii, nikt nie chce o tym rozmawiać. Jeśli napiszesz coś na ten temat w mediach społecznościowych, zostaniesz natychmiast zablokowany, a twoja treść zostanie oznaczona jako „dezinformacja”.
Dlaczego tak ważne jest unikanie szczepień jak ognia? Wystarczy spojrzeć na wszystkie użyte składniki, w tym na konserwanty, emulgatory, adiuwanty, genetycznie modyfikowane bakterie, zmutowane wirusy i środki sterylizujące. Wszystko to jest ogłaszane publicznie. Nikt nigdy nie powinien wstrzykiwać sobie tego środka do krwiobiegu lub tkanki mięśniowej, gdyż omija on naturalne mechanizmy obronne organizmu, w tym skórę, płuca i przewód pokarmowy. Te toksyczne i czasami śmiertelne składniki obejmują rtęć (duże dawki w szczepionce przeciw grypie!), krew ludzką (albuminy z aborcji), śmiertelne wirusy świń zwane cirkowirusami (w szczepionkach rotawirusowych Rotateq), krew orła, krew psa, zakażone komórki nerek małp zielonych, sukralozę, glutaminian sodu (MSG), krew krowią i kurzą, jaja, produkty mleczne, antybiotyki, olej arachidowy (stąd wszystkie te śmiertelne alergie na orzeszki ziemne), lateks (z osłonek igieł i fiolek, które przebijają igły), aluminium i wiele innych.
